How AI Agents Reshape Knowledge Work
Autonomy, Efficiency, and Scope

AI products and user behavior evolve together, continually reshaping what AI can do, how people use it, and where the economic gains accrue.
Over the last few years, frontier products have progressed from conversational assistants (e.g., chatbots) to copilots to agents. As capabilities improve, these products can narrow the gap between intelligence and utility, reshaping workflows, changing the mix of work activities, and unlocking new sources of value.
To understand this transition, we released a descriptive paper and article last year on how people use AI agents. The obvious next question is how such usage maps to downstream outcomes. In a new study, we address this question using data from Perplexity’s Search (conversational assistant) and Computer (agent) products.
We focus on three interrelated pieces:
Autonomy: how much autonomous work do agents perform versus conversational assistants on the same task? This is the key that unlocks other downstream impacts. Agents complete tasks autonomously, so users spend less time manually running workflows and more time specifying goals, checking outputs, and asking for extensions. Their roles move from operator to supervisor.
Efficiency: how much time and cost do agents save relative to conversational assistants on the same task? Autonomy changes the cost structure. Agents replace manual implementation with machine execution, lowering the marginal cost of each step while raising the fixed costs of specification and verification. This also means the efficiency advantage is stronger for longer tasks.
Scope: how do agents change the kind of work users attempt? Autonomy also changes the scope of work. By automating the generative parts of tasks that often require specialties, agents allow users to branch into domains outside their core expertise and attempt tasks that are costly to produce but relatively easy to verify.

The progression of frontier AI products
As background, let’s start with some general observations about the progression of frontier AI products. I group them roughly into 4 categories—conversational assistants, copilots, specialized agents, and general agents.
Conversational assistants primarily support isolated information exchange with limited context or ability to act. Copilots embed these capabilities into existing tools and workflows, co-working with users to complete tasks within those tools’ interfaces. Agents go further: they connect across a wider range of tools in the backend and return completed artifacts with little human involvement.
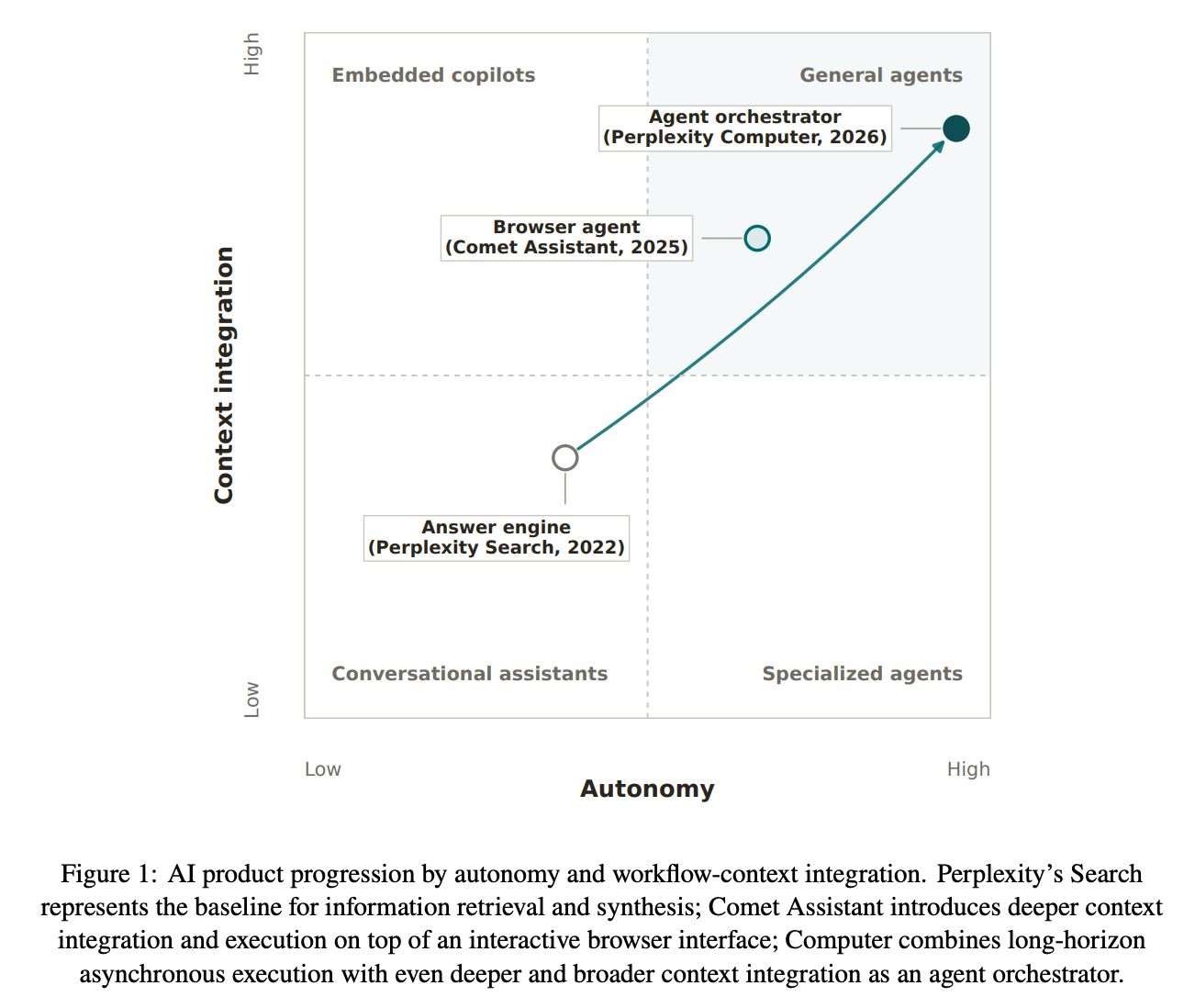
One way to characterize them is by a 2x2 matrix, with the level of autonomy on one axis and context integration on the other. Autonomy measures how long the product can run with minimal human intervention. Context integration measures the surface area of the digital environments the product can read from and write to.
The figure below situates Perplexity’s product arc, but we can also map other AI products. Early ChatGPT sits in the assistants quadrant; Cursor fits in copilots; Claude Code and Codex land between specialized (coding) and general agents; and Claude Cowork and ChatGPT’s agent mode belong in the general agents quadrant, etc.
It is important to fix the baseline when evaluating the impact of agents. We take conversational assistants as a conservative baseline1 and anchor our analysis on the comparison between Perplexity Search and Computer.
Adoption and use cases
We look at the growth of Computer and what people use it for over the first three months after launch, from February 27 to May 27, 2026.2
Finding 1: Computer grows faster than the Search baseline.
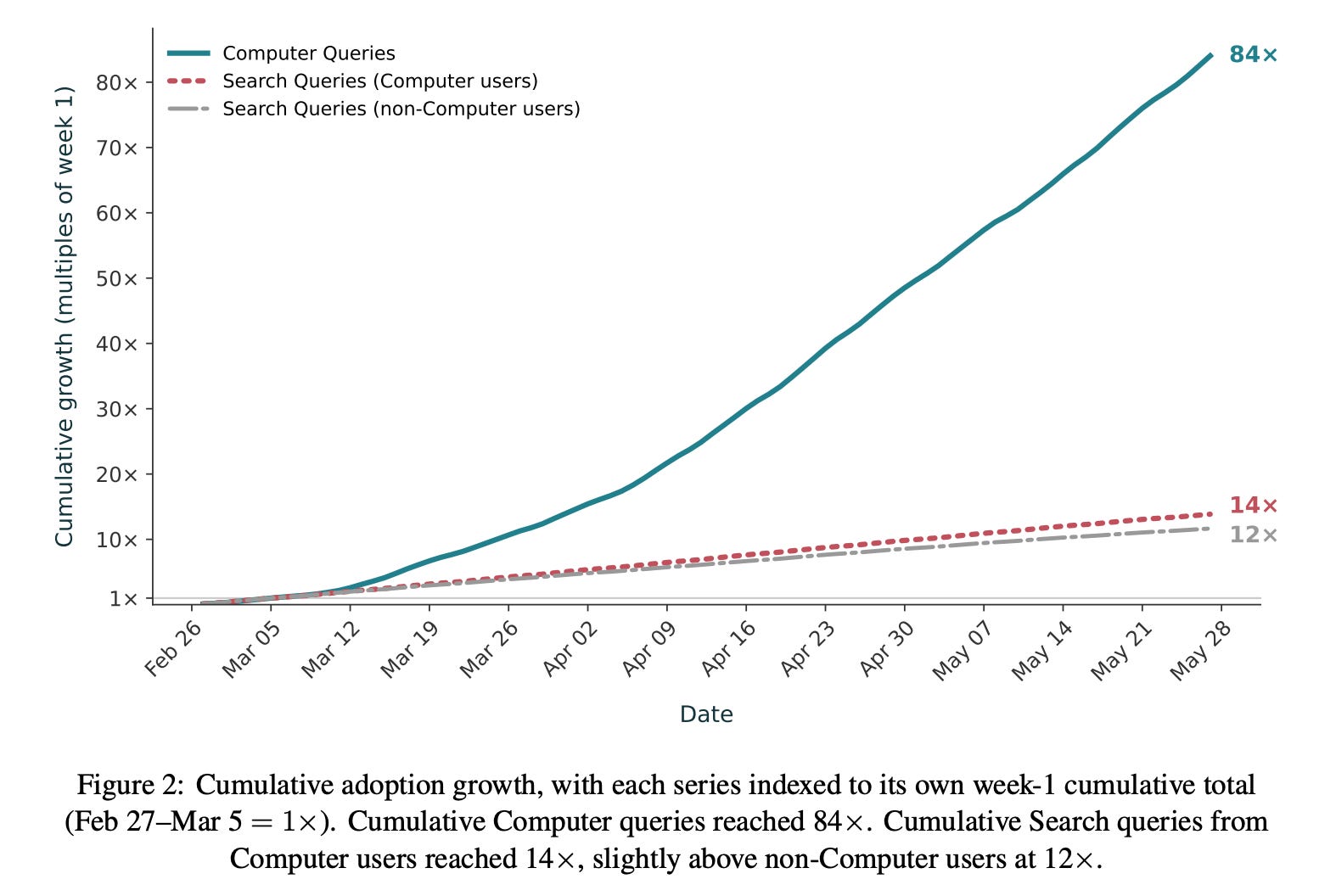
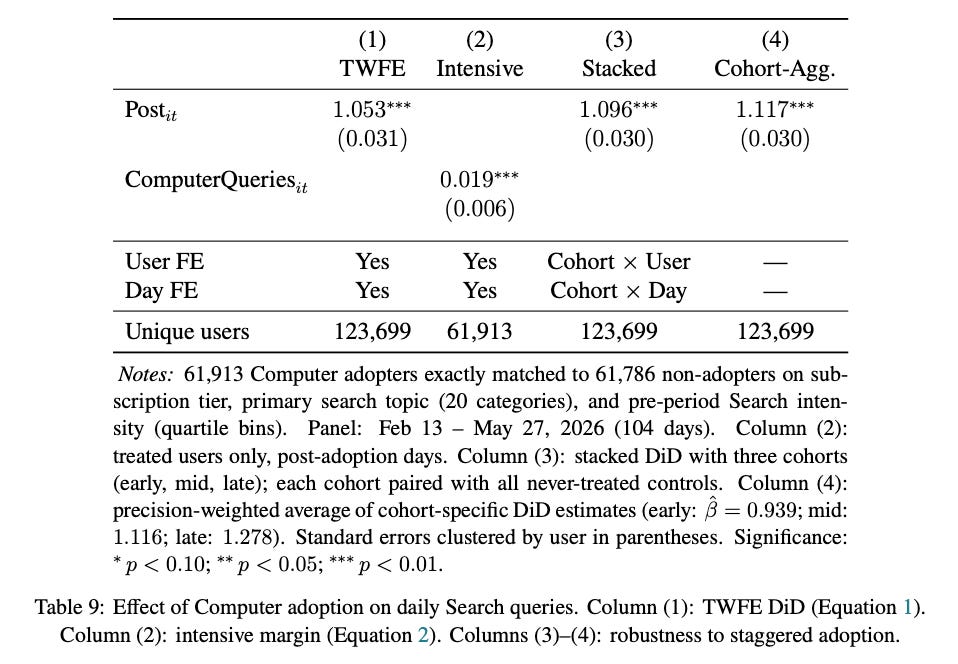
Finding 2: A matched-sample difference-in-differences analysis shows that Computer and Search are complements: Computer adopters subsequently issue more Search queries per day than similar non-adopters.
This is not obvious ex ante: our theoretical analysis highlights two countervailing forces. On the one hand, users might substitute Computer for Search on longer tasks, reducing Search usage. On the other hand, Computer can free up time to attempt additional shorter tasks where Search has the cost advantage, increasing Search usage. The result points toward the latter being more prominent.
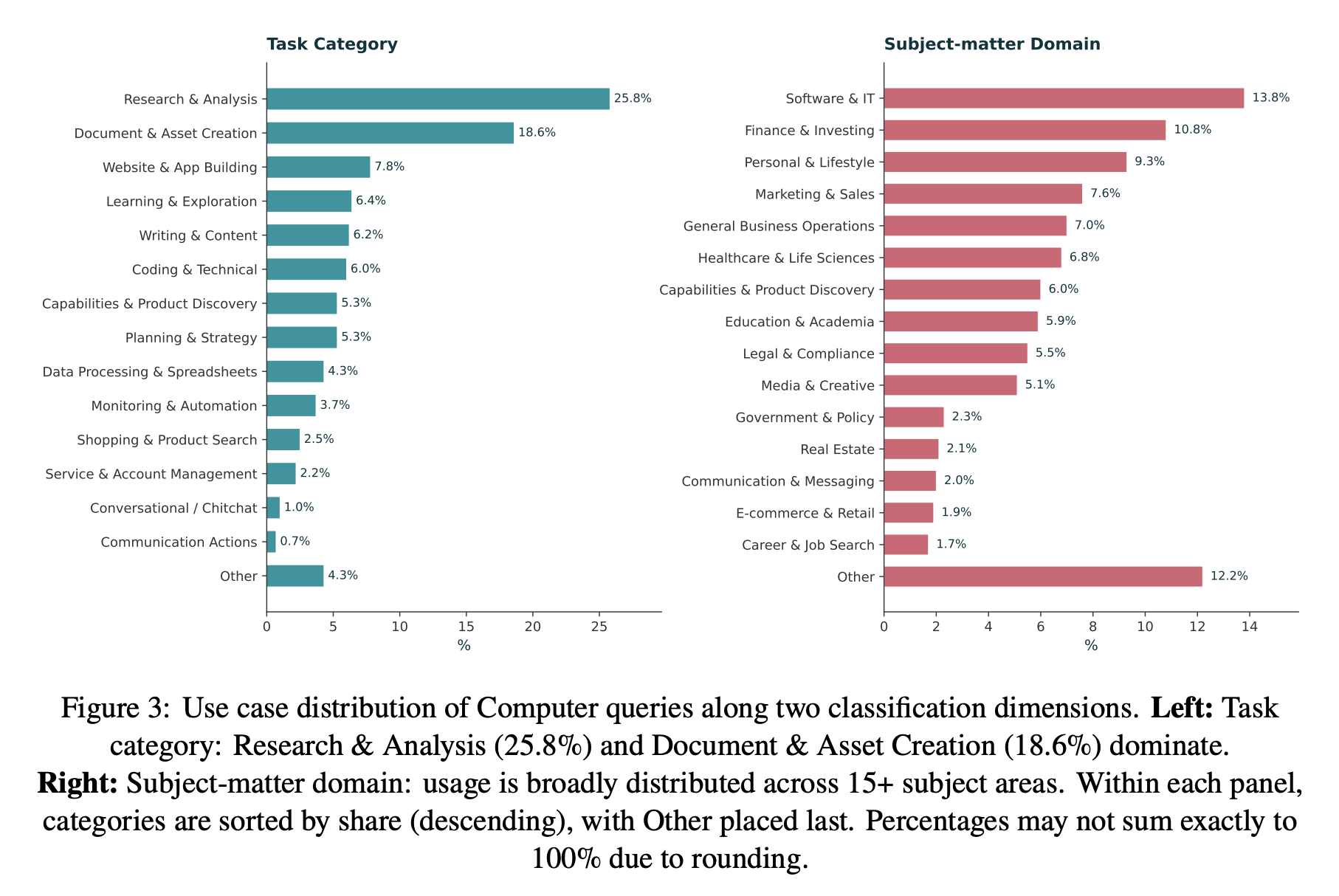
Finding 3: Computer is mostly used for research and artifact production, across a broad set of knowledge-work domains.
Autonomy
A direct comparison between Computer and Search is complicated by endogenous task selection: users may send different types of queries to each product. Ideally, we would compare outcomes for the same task performed with Computer versus Search. To approximate this, we construct a sample of matched sessions that proxy for the same task by exploiting user-generated natural experiments, where the same user submits near-identical initial queries (the first message in a session) to both products.3
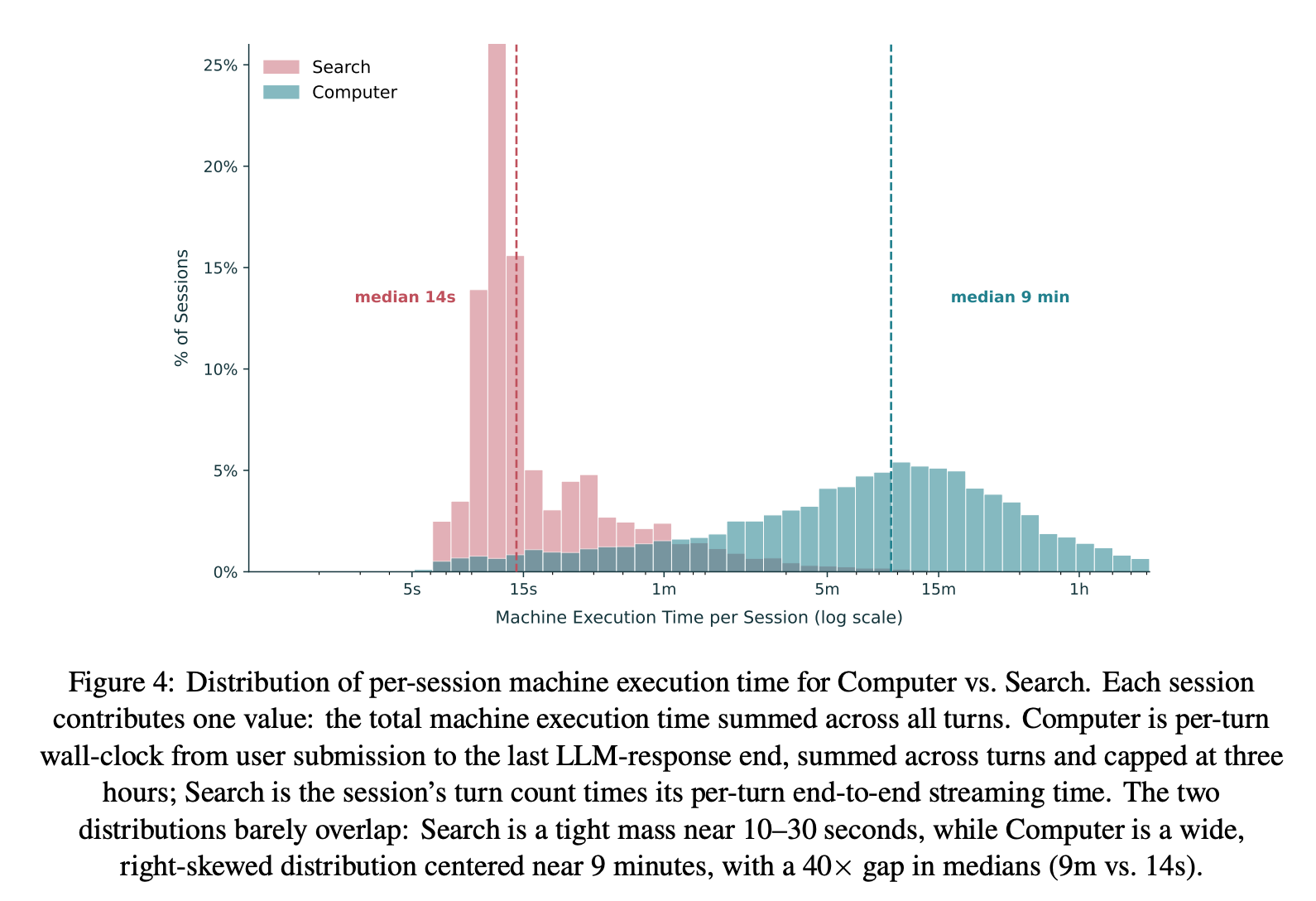
Finding 1: Computer executes roughly 40× more machine work per session at the median and 48× more at the mean, relative to Search.
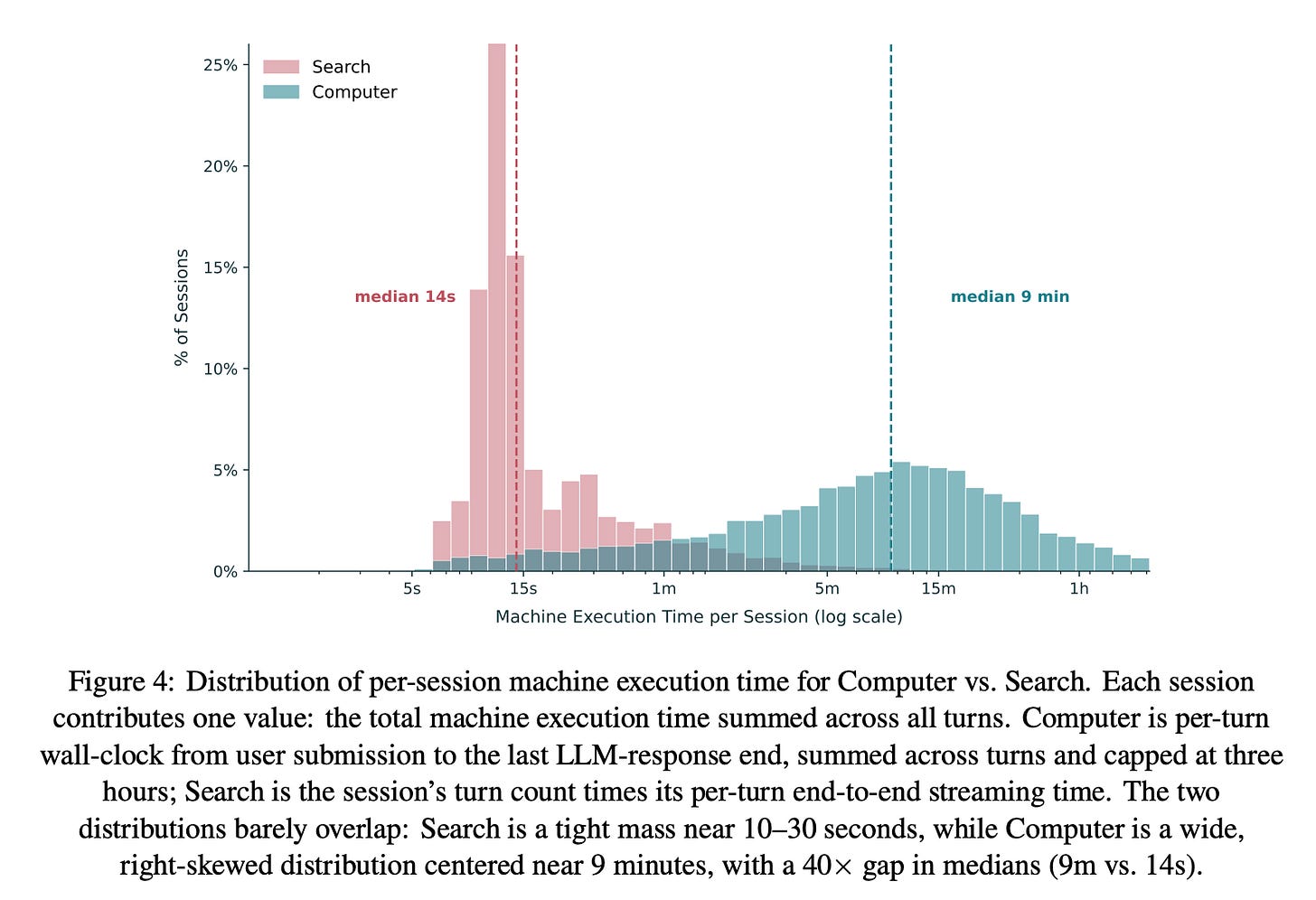
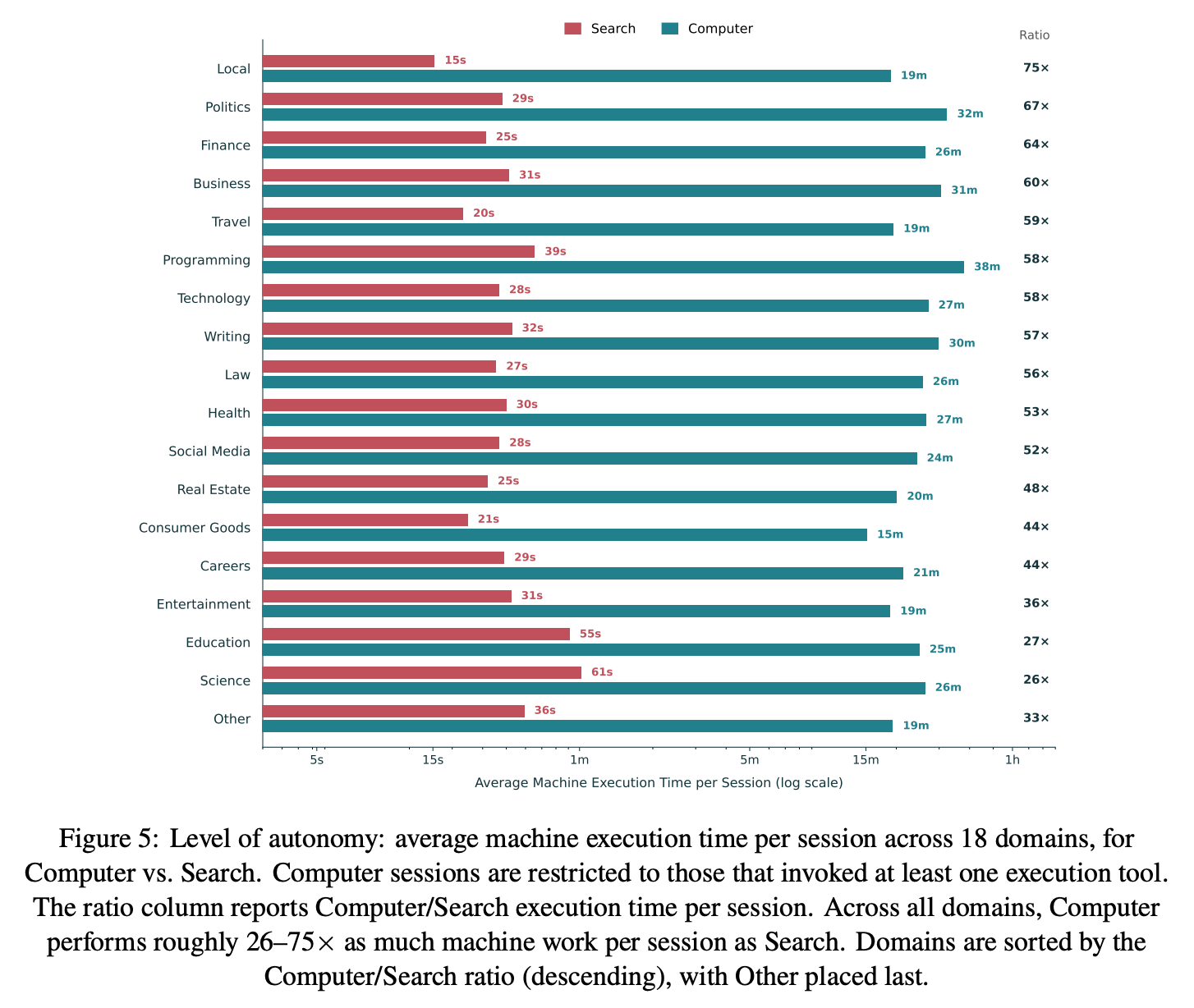
Finding 2: The autonomy gap is consistently large but also varies by domain.
Finding 3: Computer pauses more often to ask for permission and clarifying questions, yet users are no more likely to stop it than Search.
At the query level, 13% of Computer queries invoke at least one pause-for-user tool during execution, versus 0.3% of Search queries; at the session level, the rates rise to 38% versus 0.8%. Because Computer runs longer, more complex actions, it more frequently pauses to request critical input from the user, helping ensure that the final output matches what the user actually wants. At the session level, most pauses come from approval prompts (24.2% of sessions), followed by open clarifying questions (16.9%) and structured input requests (2.3%).
Despite Computer’s longer runtimes, user-initiated interruptions are similar across products: 3.7% of Computer sessions contain at least one user stop event versus 3.4% of Search sessions. Users are no more likely to abandon a long autonomous Computer run than a short Search response, suggesting that once launched, Computer’s autonomous execution is largely trusted to run to completion.
Finding 4: Computer makes more external tool calls.
Another indicator of autonomy is how often Computer chains external tools—via Model Context Protocol (MCP) or other API connectors—into a single session, work that a Search user would typically perform manually across separate apps.
7.9% of Computer sessions invoke at least one connector call versus 1.8% of Search sessions, and the mean number of connector calls per session is 1.19 for Computer versus 0.10 for Search. Among the subset of requests that use connectors at all, Computer fires an average of 15.0 calls per session compared with 5.5 for Search. These patterns suggest that Computer’s autonomy operates over a more integrated context surface, pulling in data and taking actions across a wider range of external services within a single session.
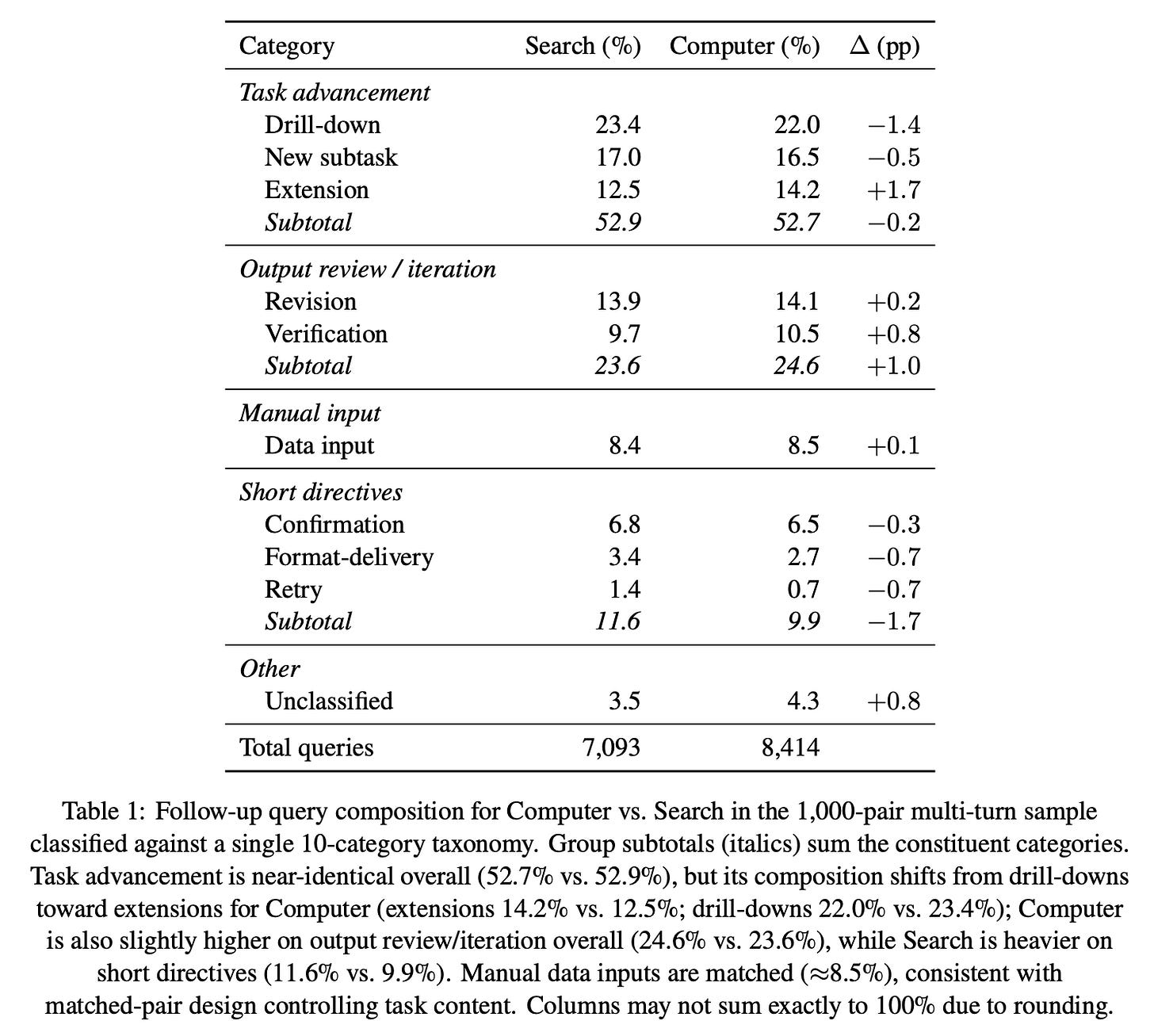
Finding 5: Computer tends to shift the follow-up query distribution towards task extension and verification.4
Finding 6: Computer also tends to produce higher quality output as measured by lower user dissatisfaction.5
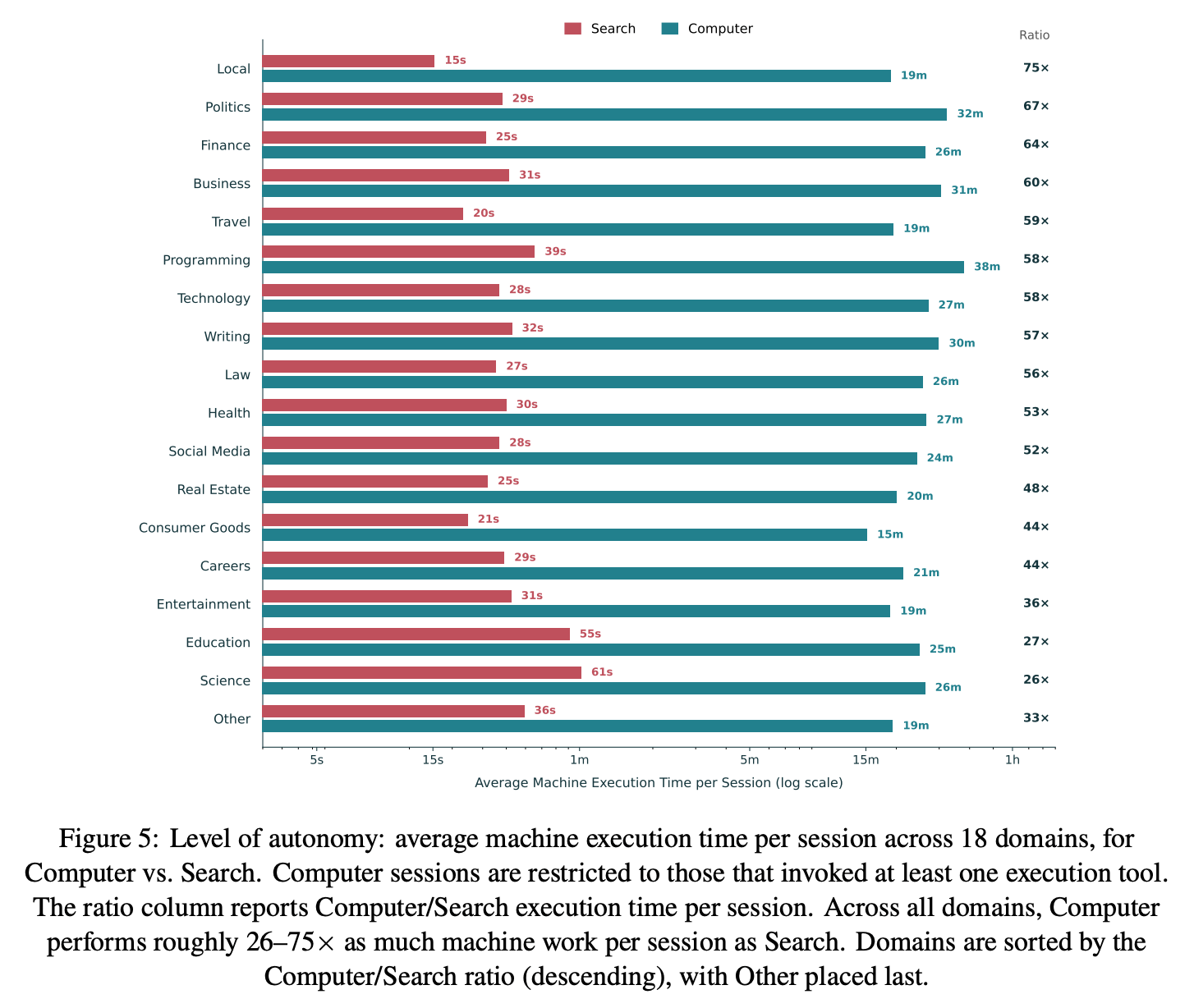
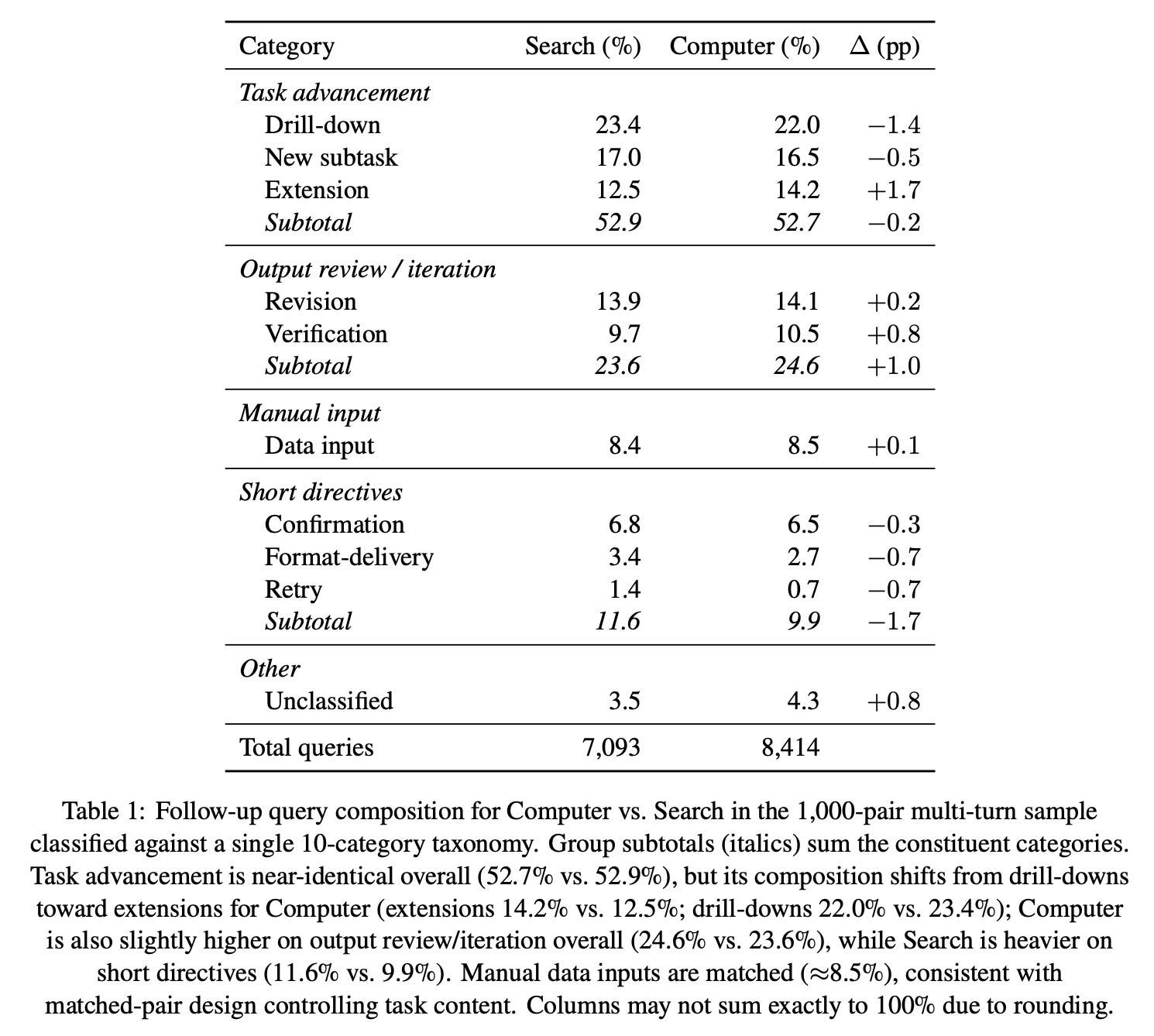
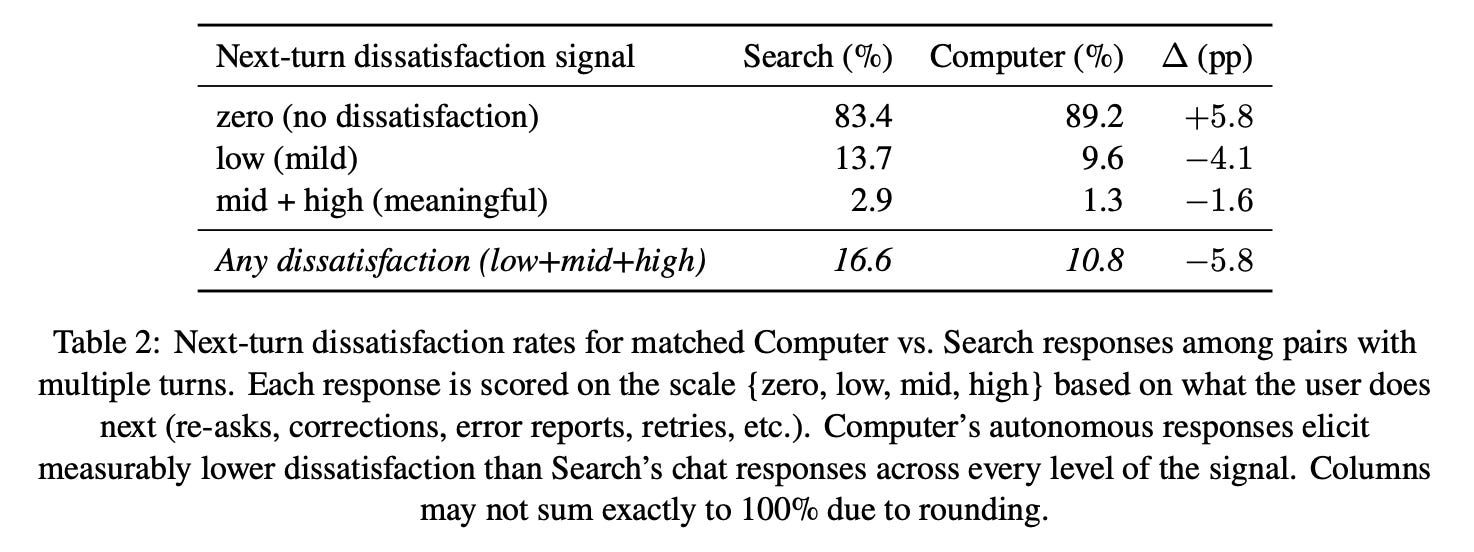
Efficiency
We next ask how Computer’s autonomy advantage maps into an efficiency advantage, as measured by task completion time and cost. To quantify this, we estimate the human and compute time and cost required to complete each matched task session under two regimes:
Search + Human, where Search handles information retrieval and synthesis, and the human manually carries out all non-research actions.
Computer + Human, where the model executes the full workflow end-to-end, and the human steps in mainly for delegation and oversight.
We do not directly observe how long a task would take a human, so we triangulate with three independent estimates:
Tool-based estimate: We classify Computer tool calls into two categories: “Search” and “Do.” Search tools correspond to information retrieval and synthesis steps that are already handled by the Search product. Do tools represent execution steps that a human would need to perform manually when using Search alone. We then estimate the time required for an experienced human to carry out these Do actions.
LLM-based estimate: We feed queries from Computer sessions into an LLM to estimate the time required for a skilled professional who receives answers from Search but must perform all execution steps manually.
User-reported estimate: We conduct 25 semi-structured interviews with active Computer users across domains and elicit pre-Computer workflows and the time those workflows would have taken.
To translate task time into cost, we use domain-specific hourly wages from U.S. Bureau of Labor Statistics Occupational Employment and Wage Statistics (May 2025).
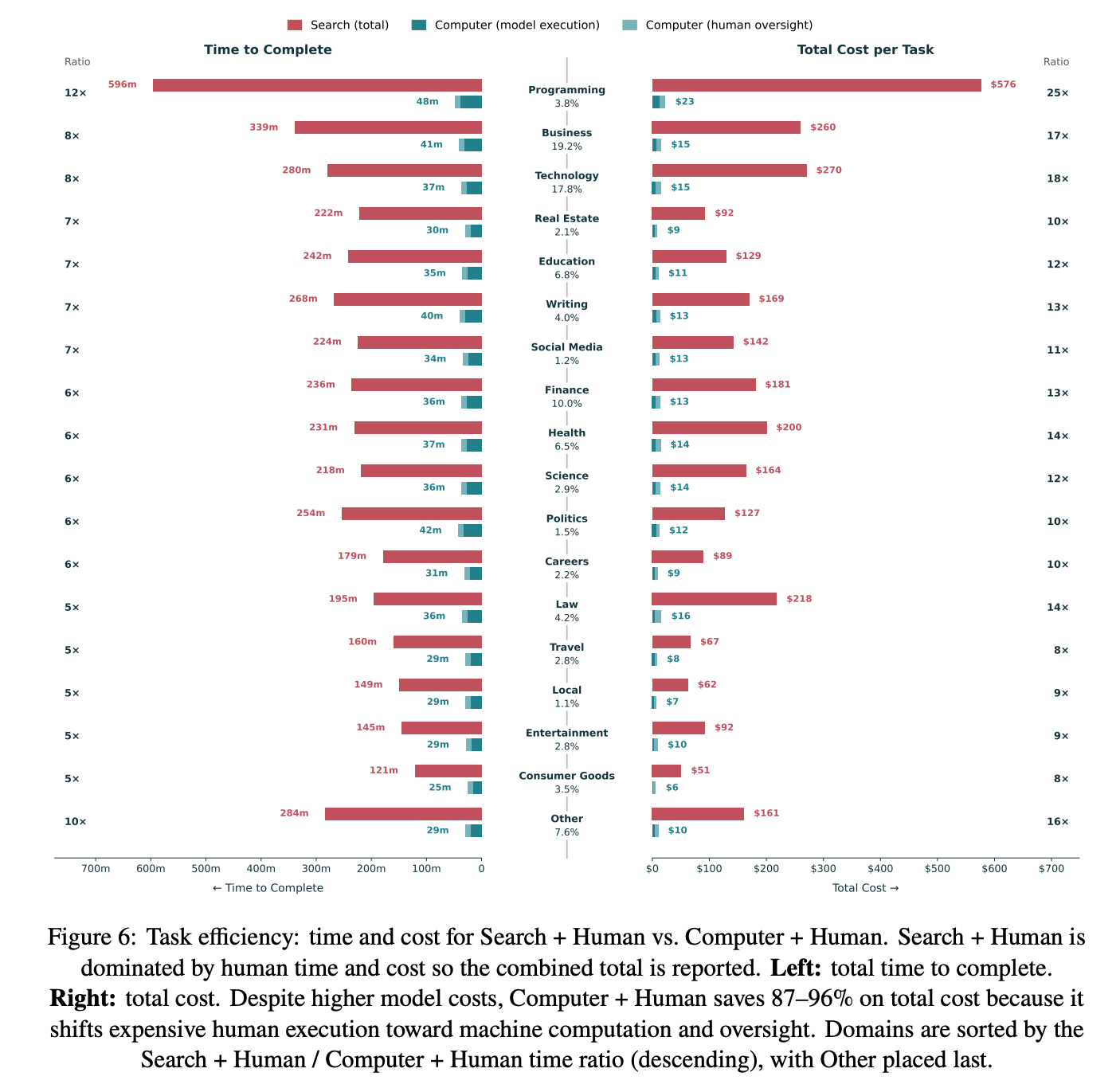
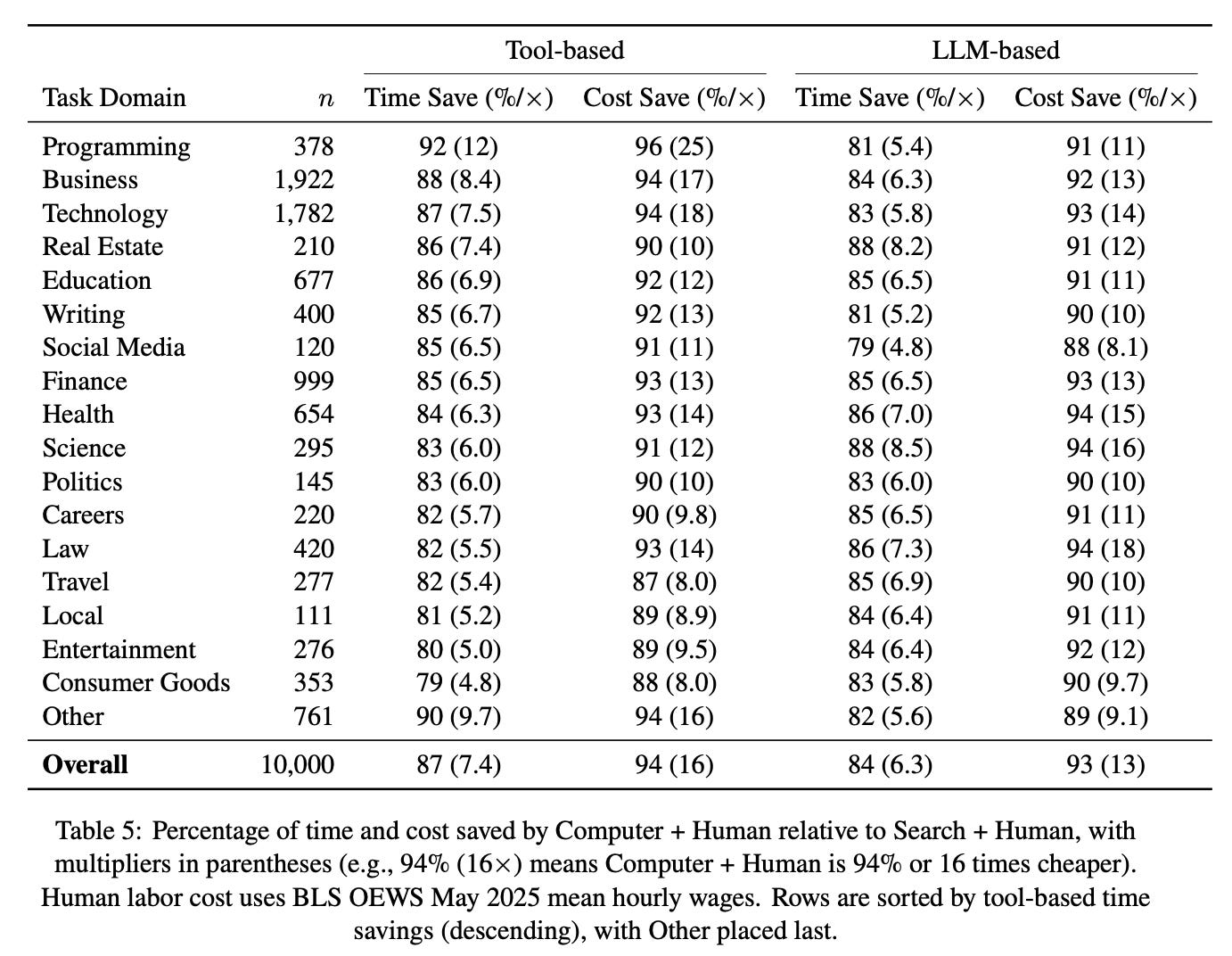
Finding 1: Tool-based estimates indicate that Computer reduces task time by 87% and cost by 94% on average, with variations across domains.
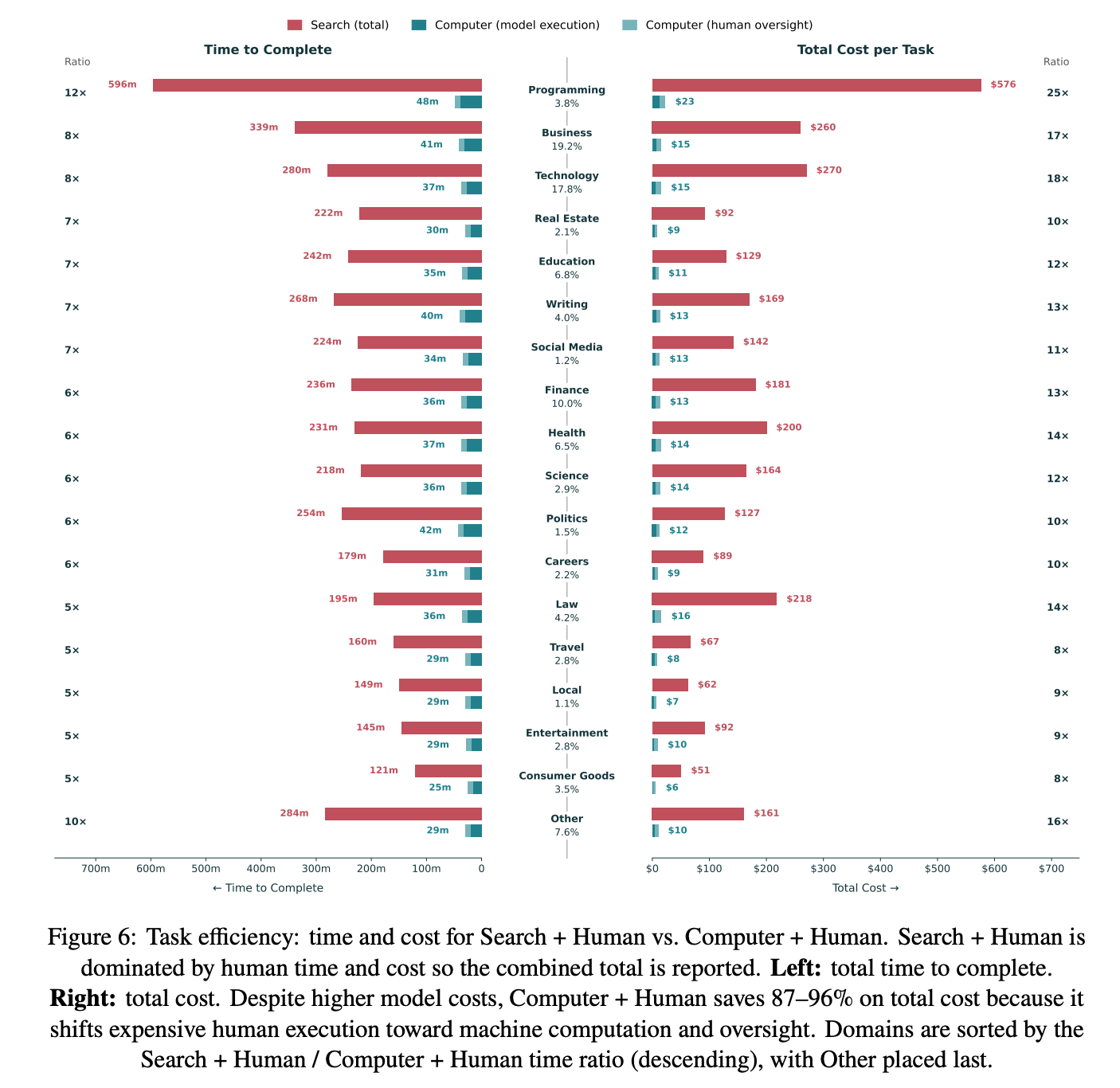
Finding 2: Breakeven analysis implies that a Search user would need to complete all execution steps in under 20 minutes to match Computer user’s total cost.
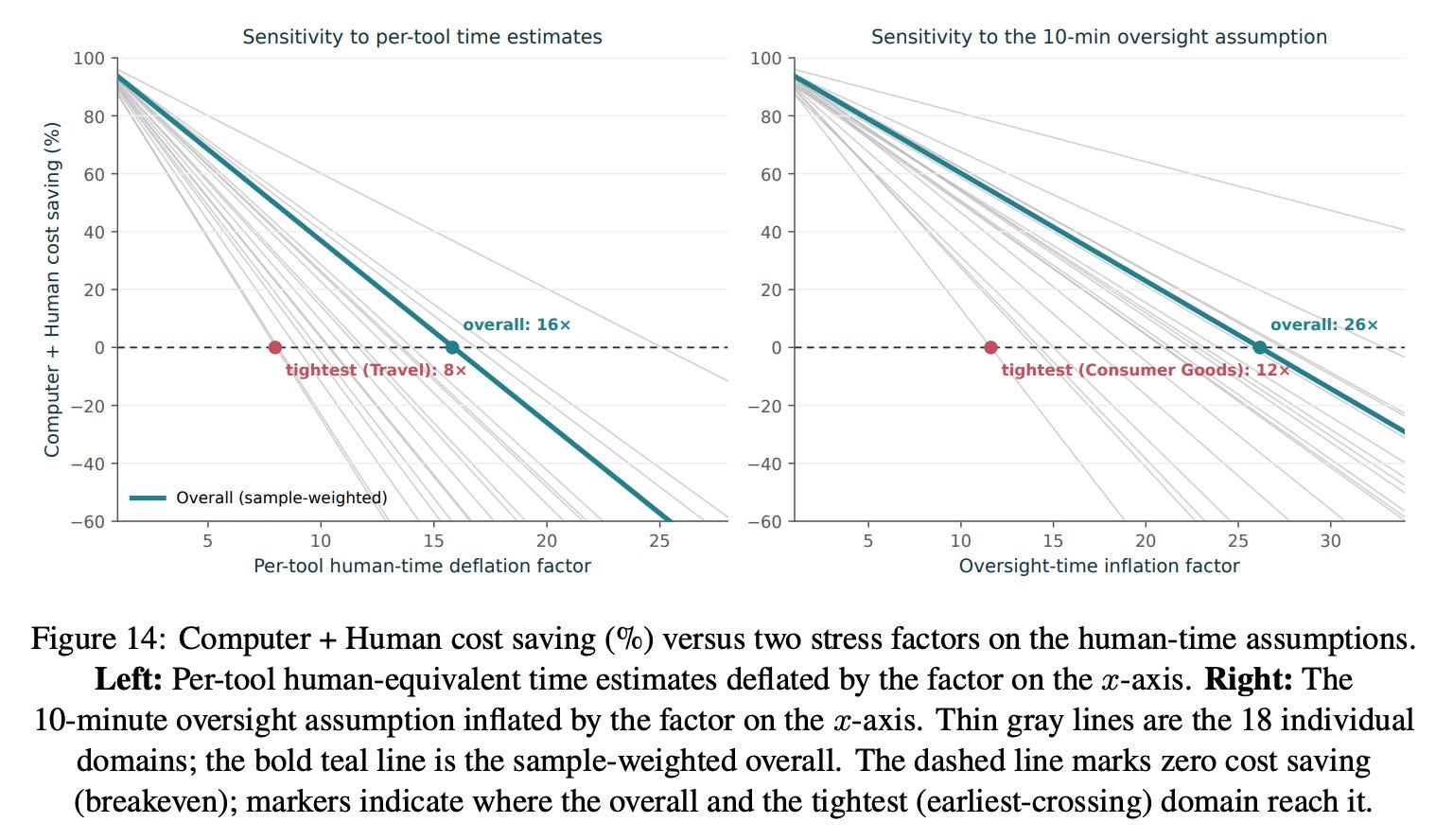
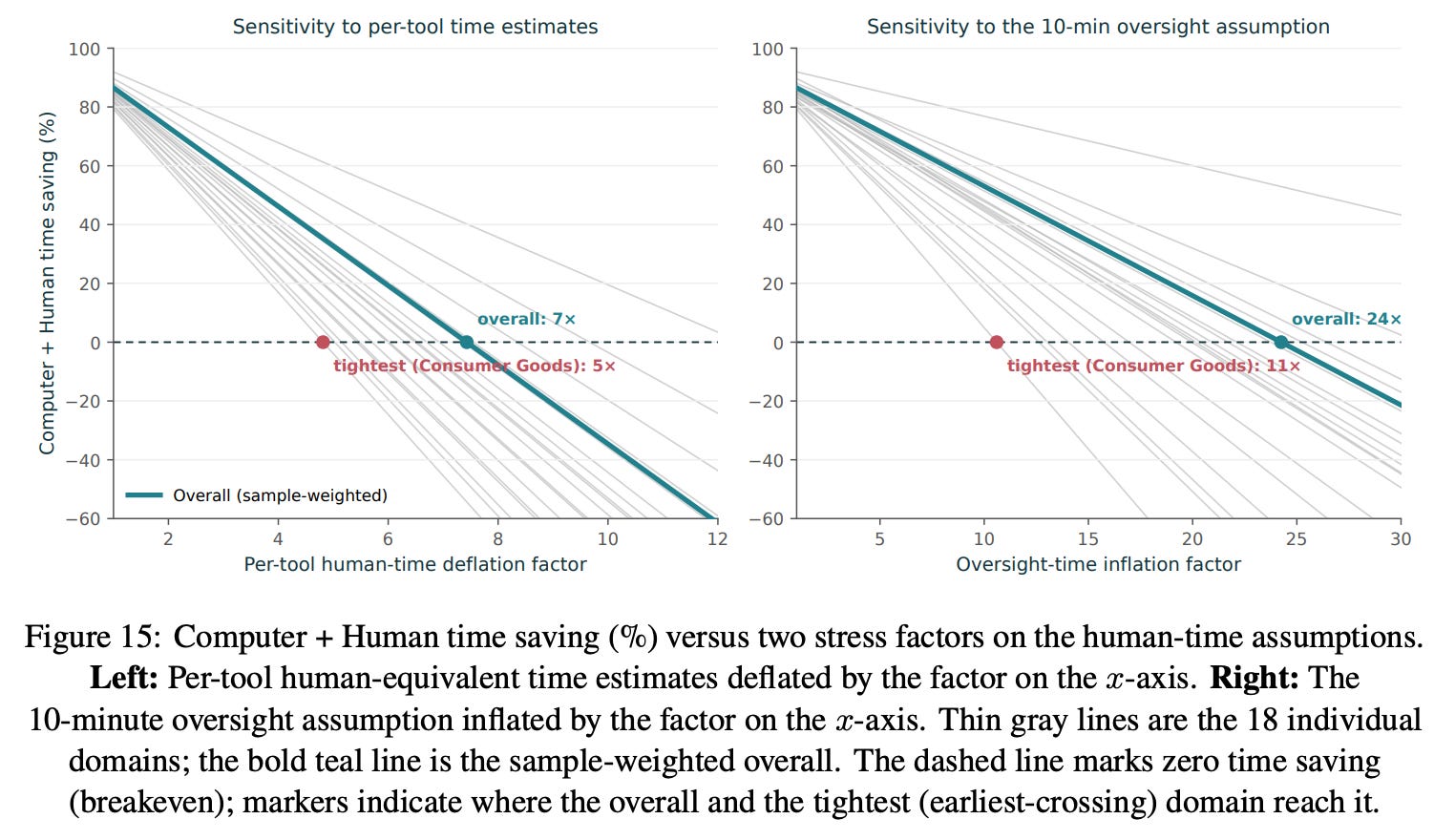
The time and cost estimates are not very sensitive to how we set per-tool human execution time or oversight time; the main results hold up across a wide range of assumptions. Even if our per-tool human-equivalent time estimates are overstated by 16×, Computer + Human still retains a sizable average cost advantage (about 8× in the tightest domain). Likewise, the 10-minute human oversight assumption can be inflated by 26× (to 260 minutes) before Computer + Human’s average cost edge disappears (about 12× in the tightest domain). The time advantage is also robust, though somewhat tighter: it survives cutting per-tool times down to 7× overall (5× in the tightest domain) and inflating oversight time by 24× overall (11× in the tightest domain).
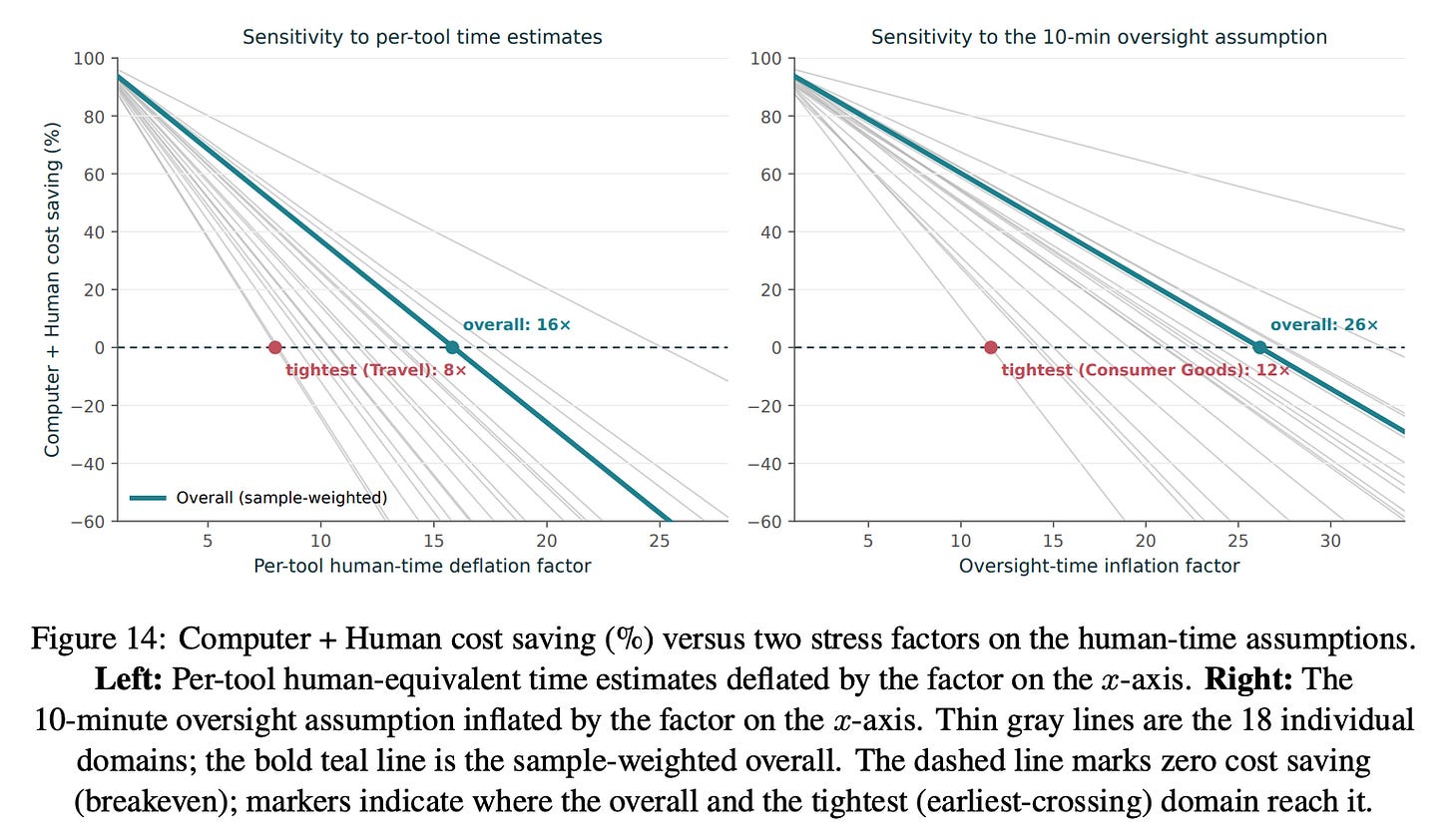
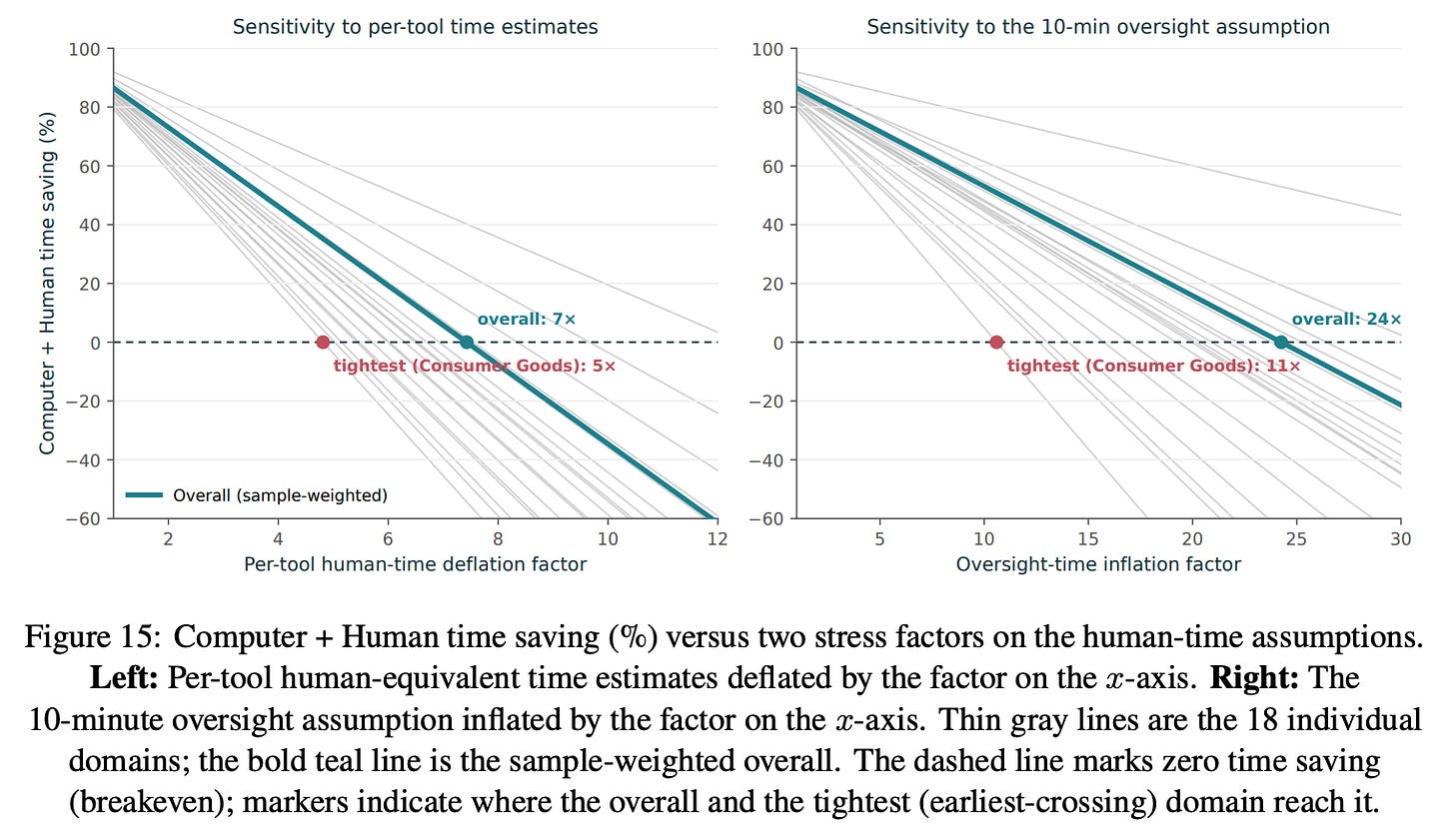
Finding 3: LLM-based estimates line up with the tool-based results, while user-reported estimates point to even larger gains.
Unlike tool-based and LLM-based estimates that hold the baseline fixed at Human + Search, the user-reported numbers reflect different pre-Computer workflows, showing a much wider range—5–300× faster and 120–750× cheaper.
Scope
The previous sections use same-user, same-task comparisons to show that Computer’s autonomous execution saves time and cost. We now turn to same-user, cross-task comparisons (between tasks attempted with Search versus Computer) to look at if Computer also enables users to expand the scope of work they undertake.
We measure scope along two axes: horizontally, whether users branch into multiple occupations, and vertically, whether they take on more complex tasks.
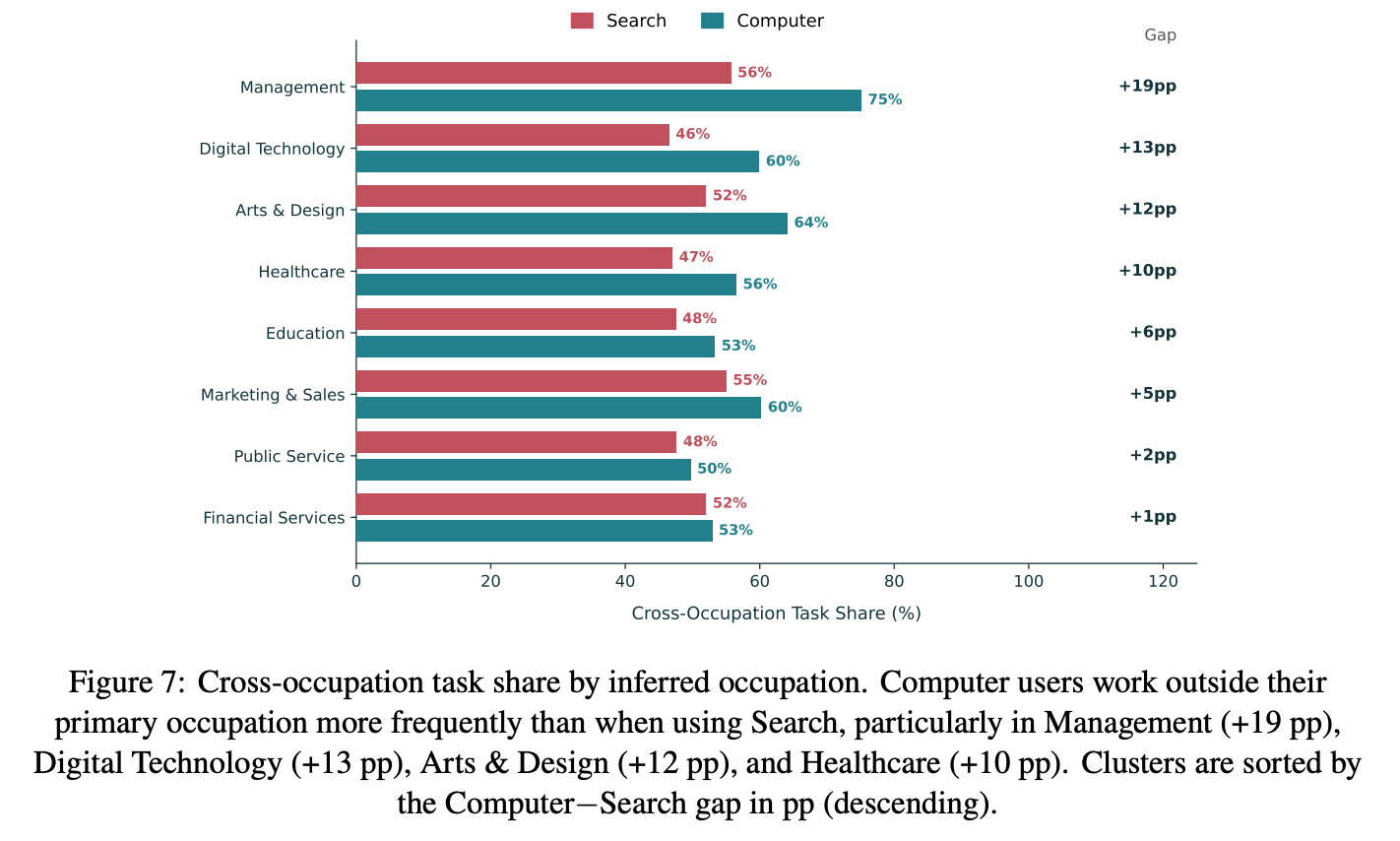
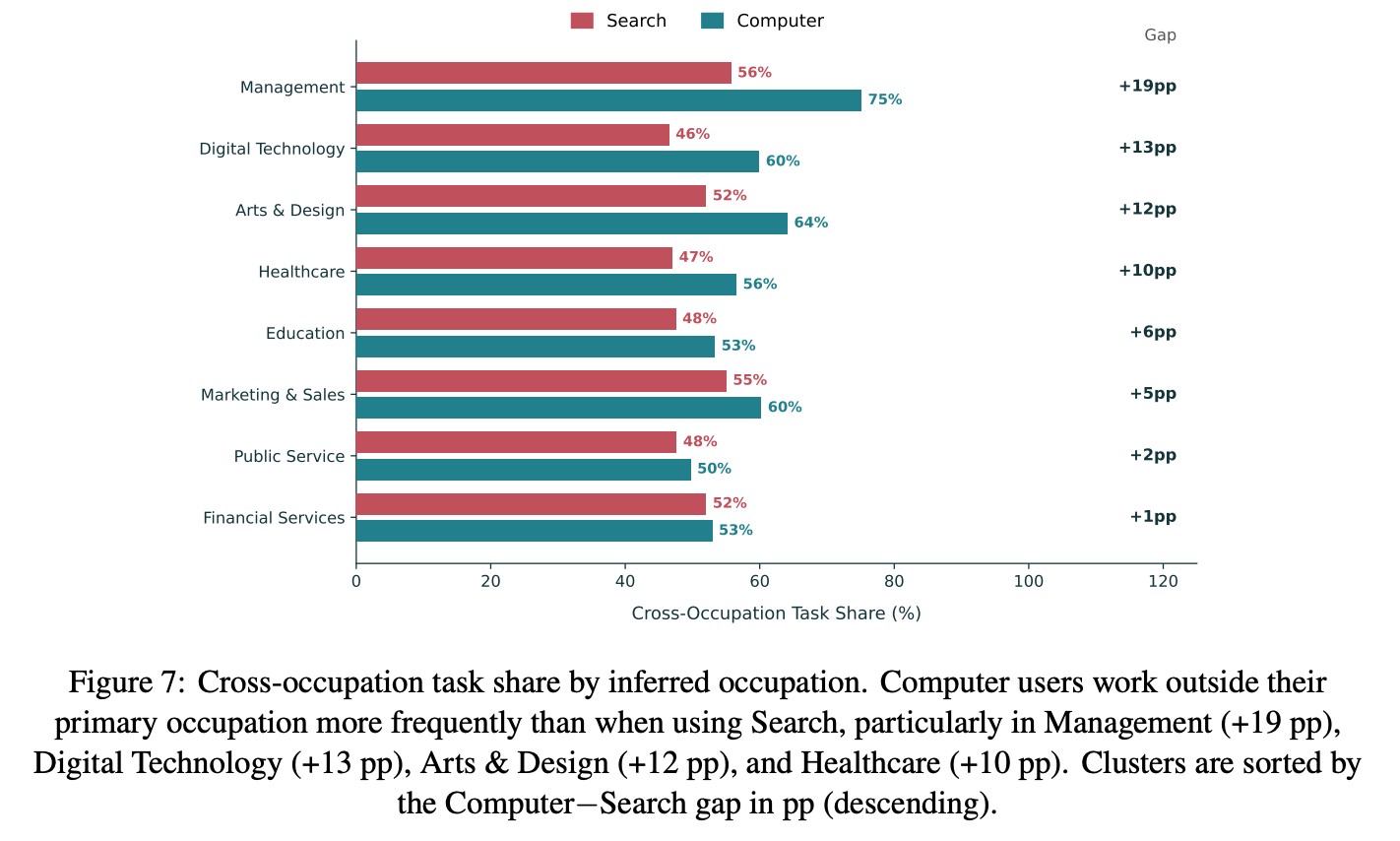
Finding 1: Computer queries are more likely to venture outside a user’s primary occupation.6
This suggests that Computer enables users to take on tasks beyond their core expertise that would otherwise require specialists, expanding the range of work they can perform and potentially reducing coordination costs.
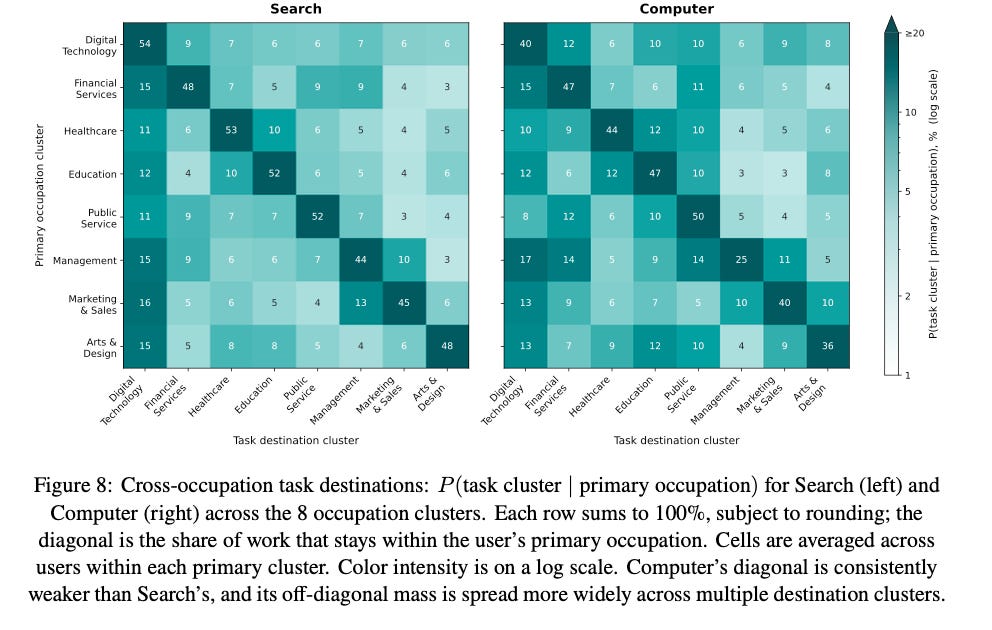
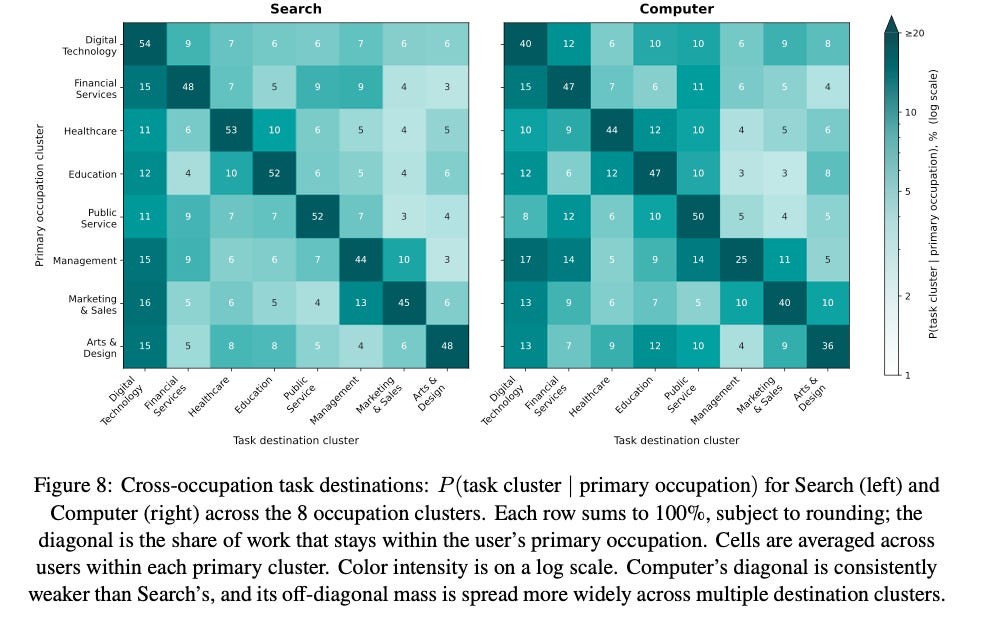
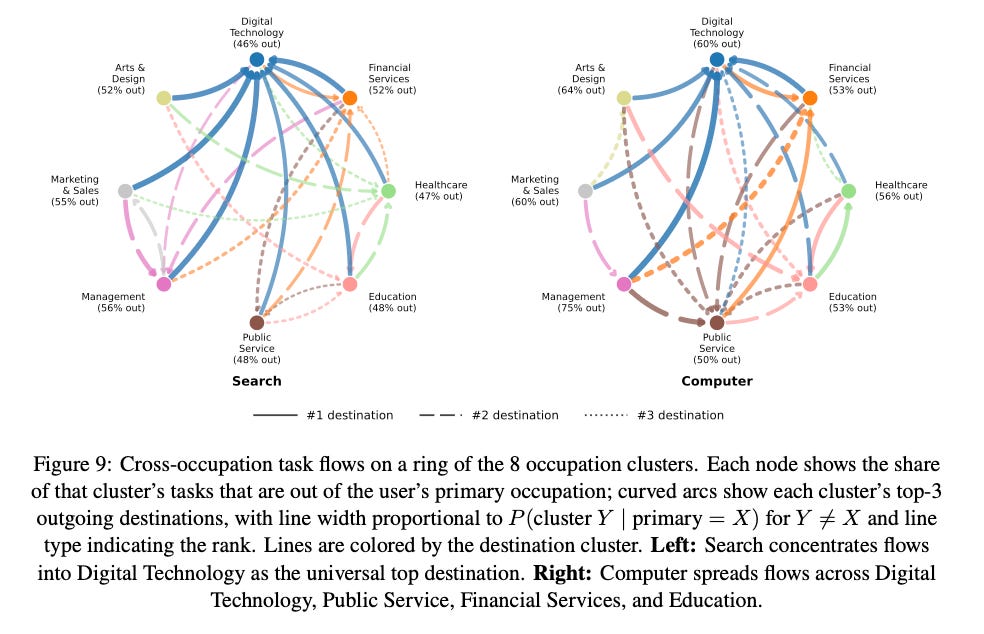
Finding 2: Among those cross-occupation queries, Search concentrates in Digital Technology while Computer is more diverse.
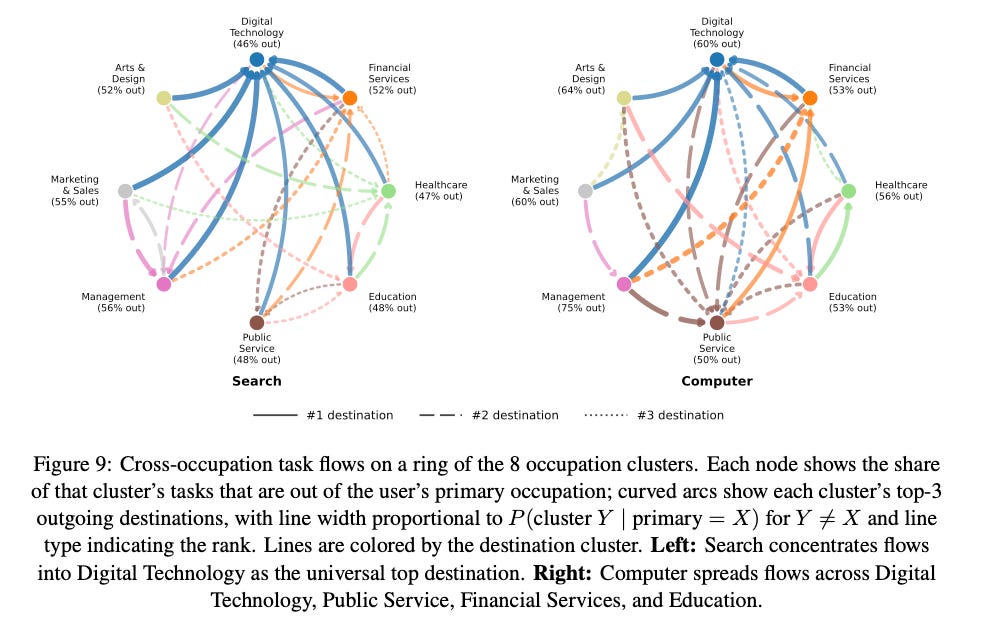
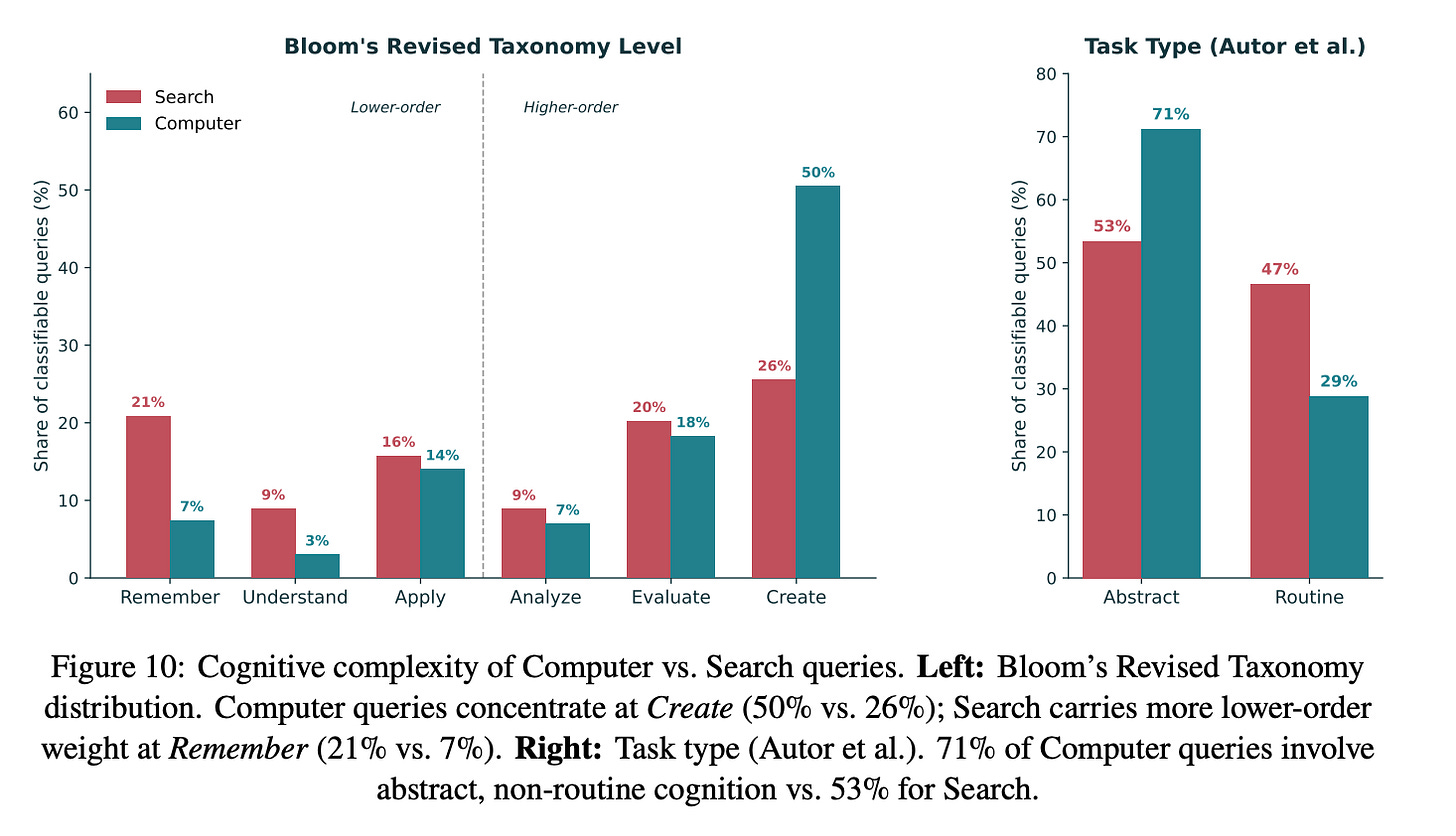
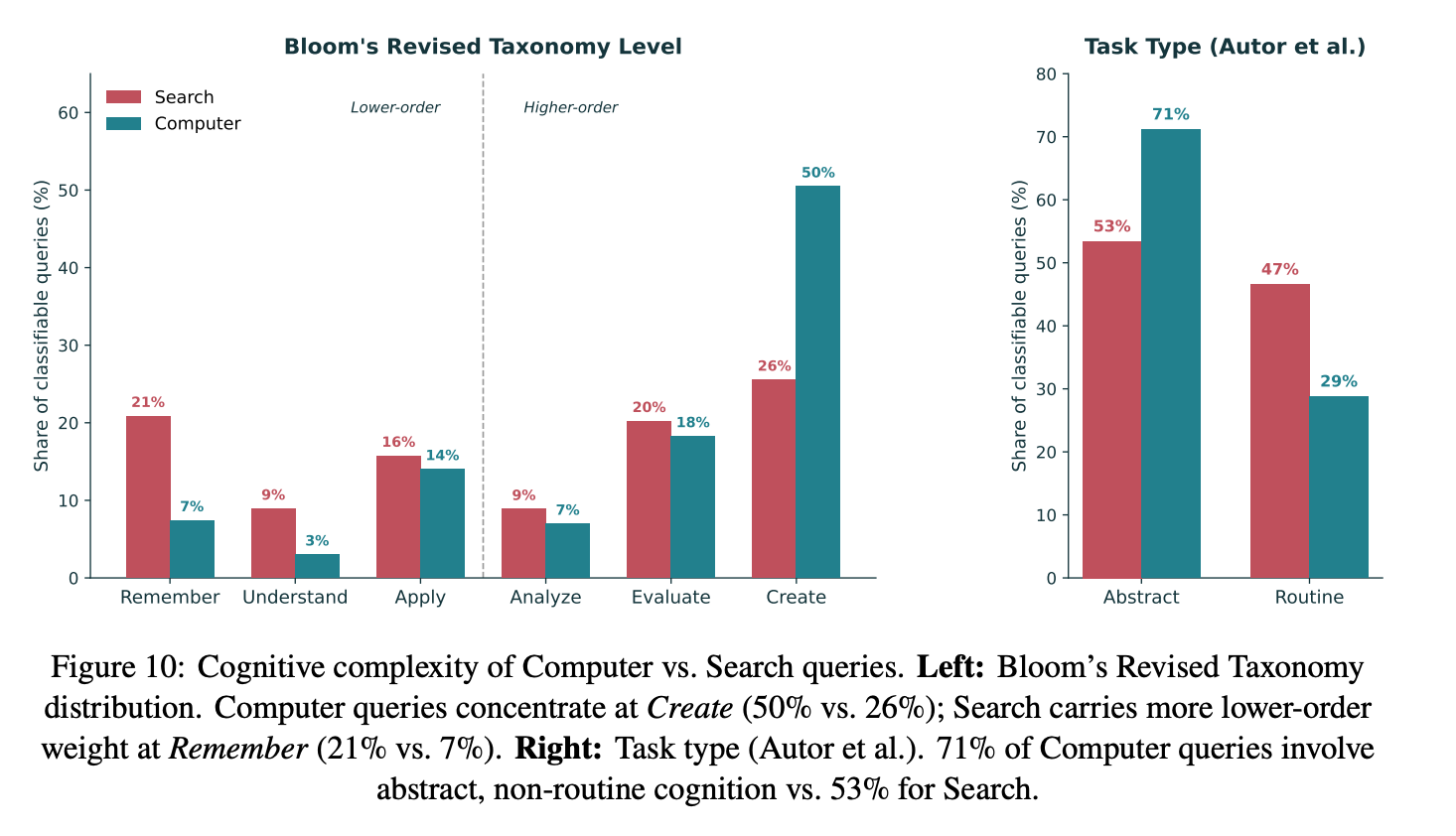
Finding 3: Computer queries are more cognitively complex. 7
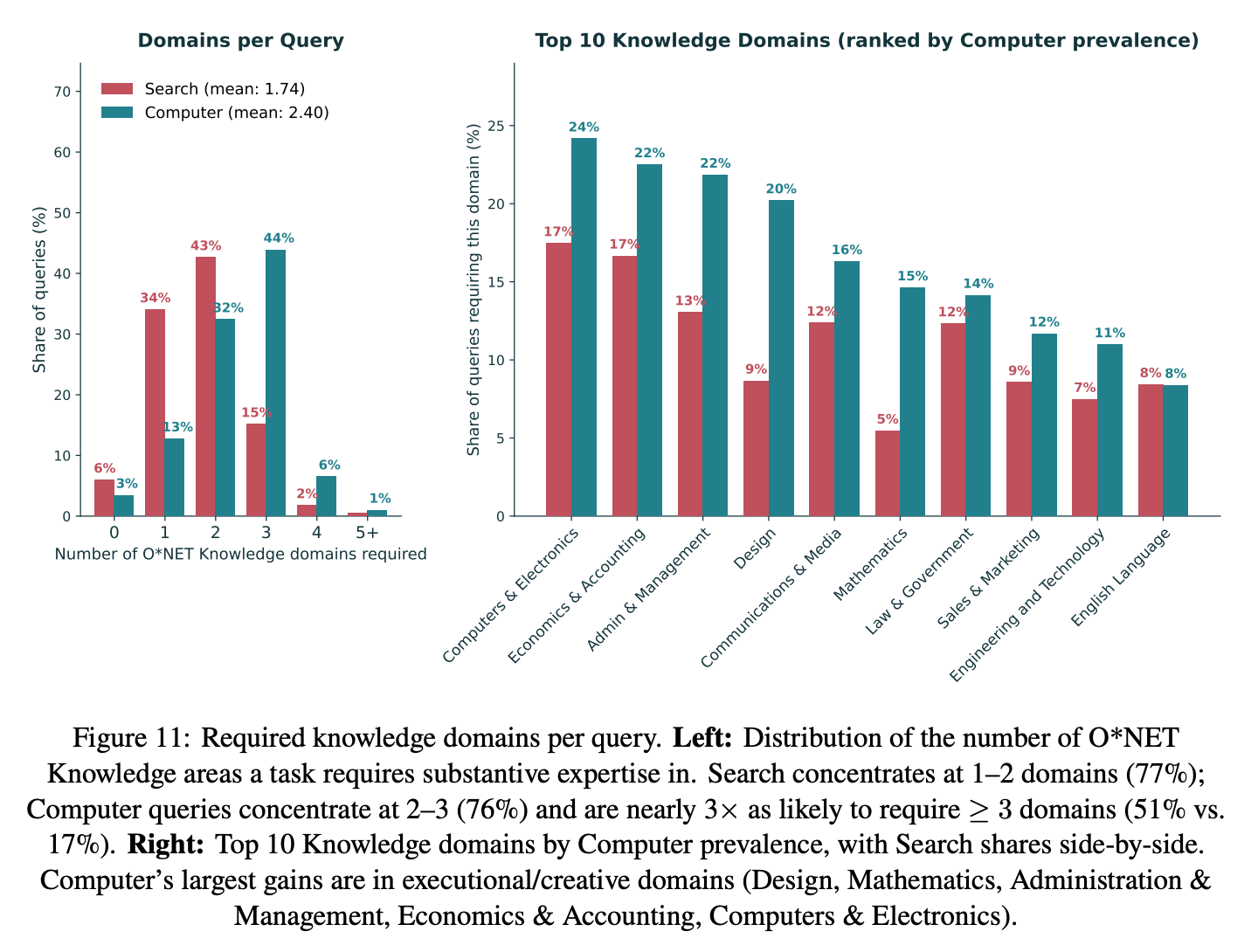
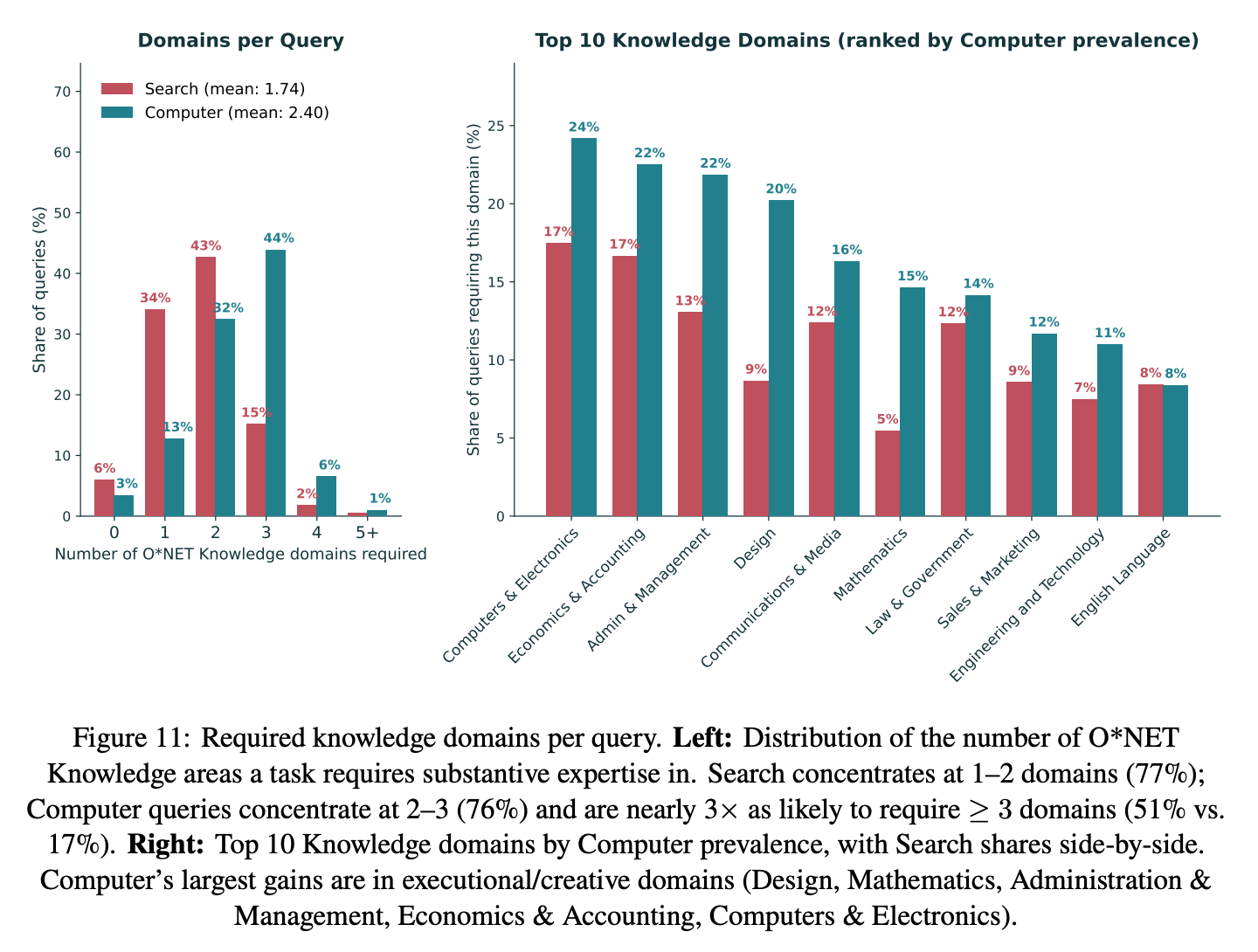
Finding 4: Computer queries tap into more knowledge domains.
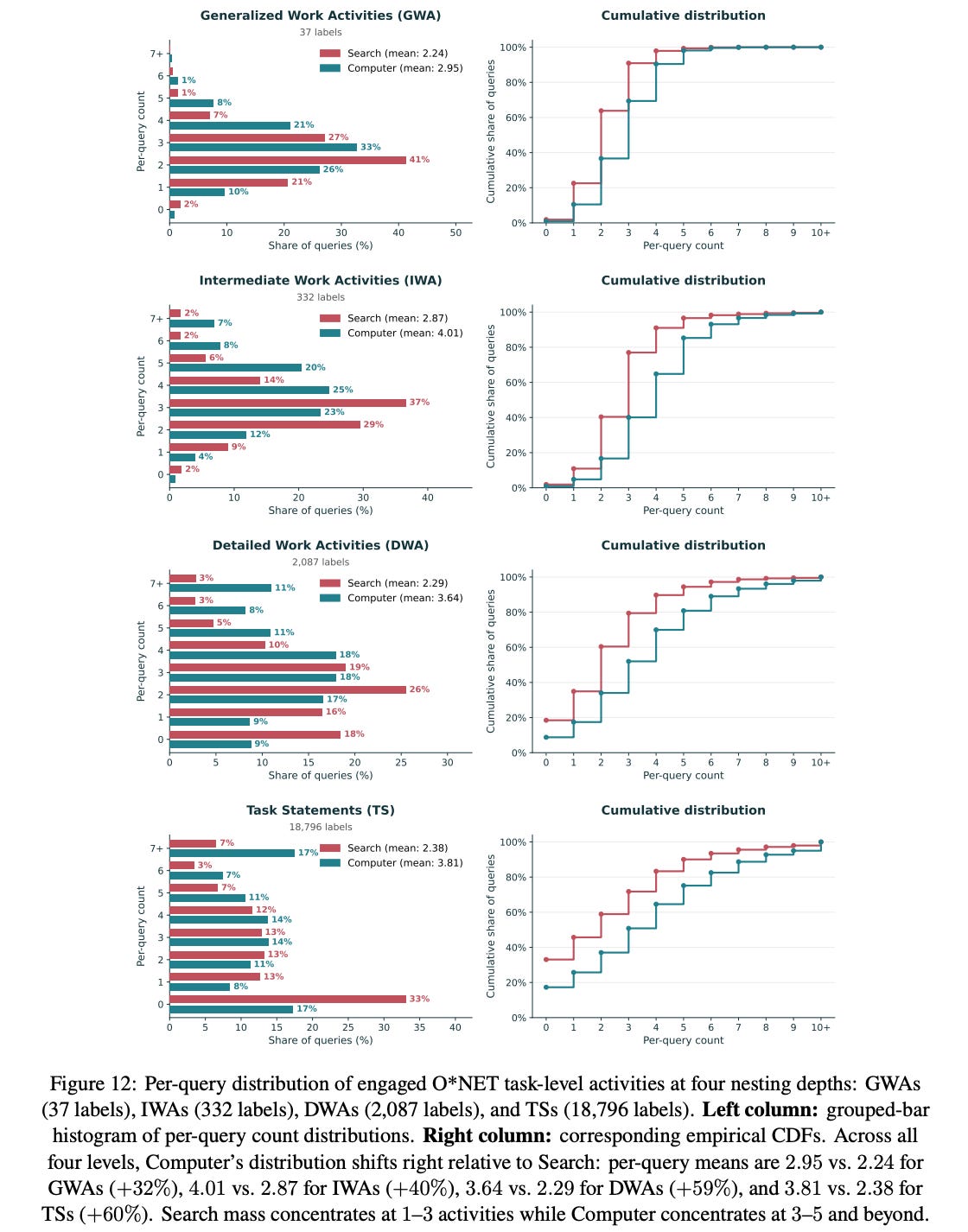
Finding 5: Computer queries cover more work activities, especially under finer-grained taxonomies.
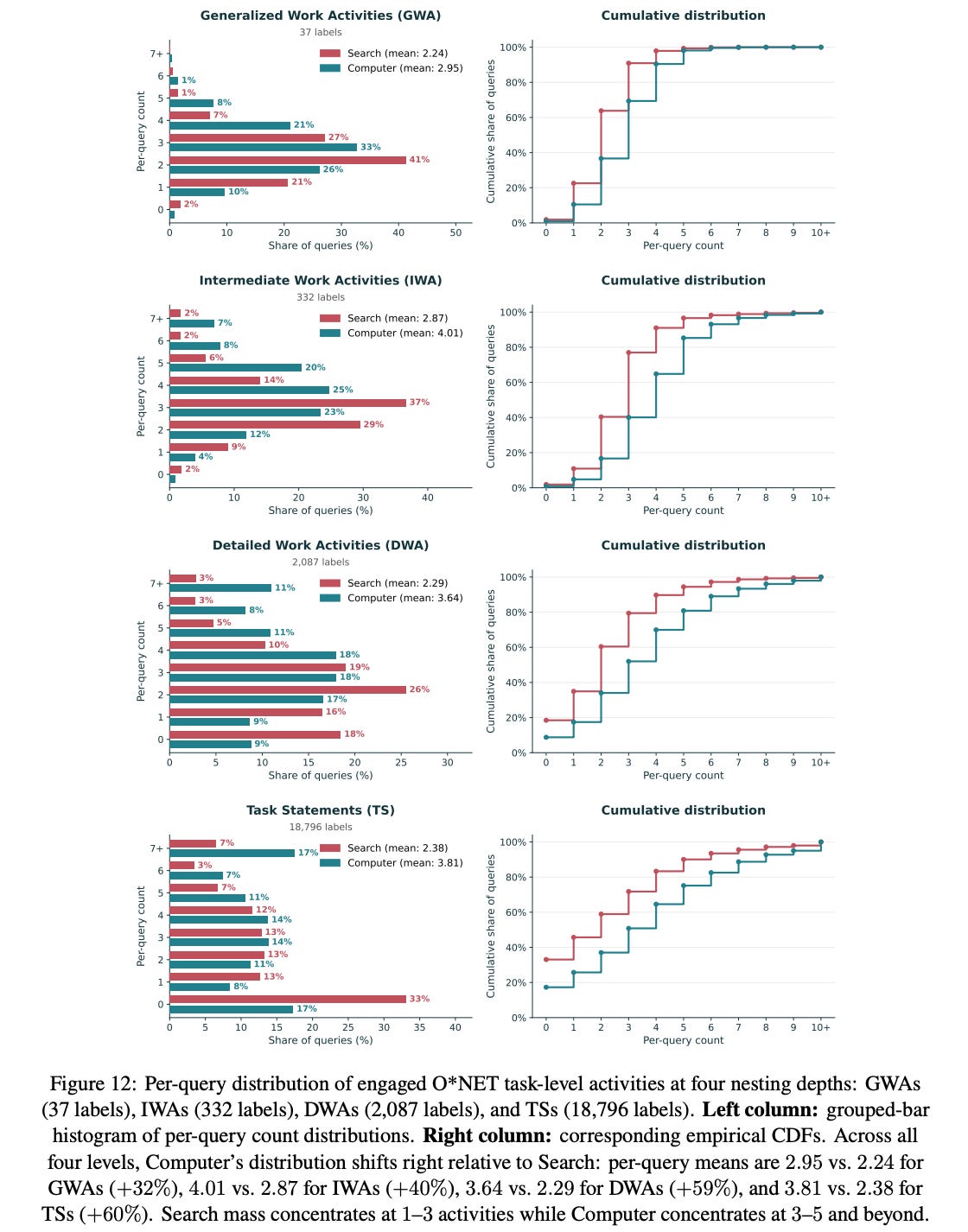
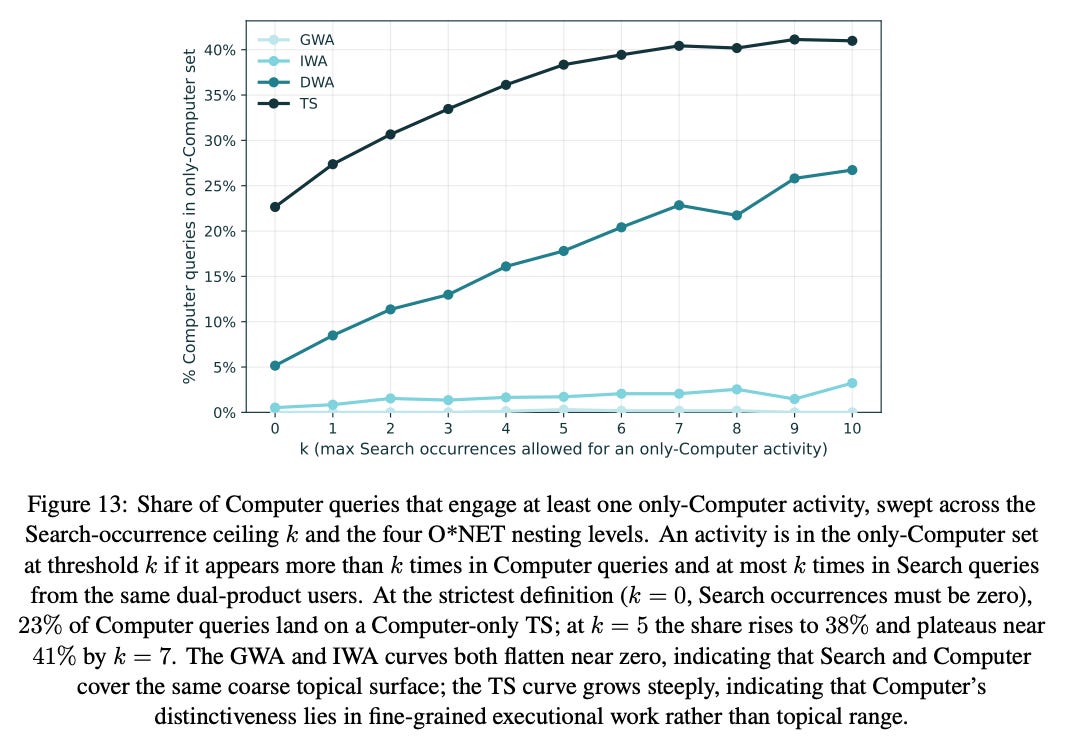
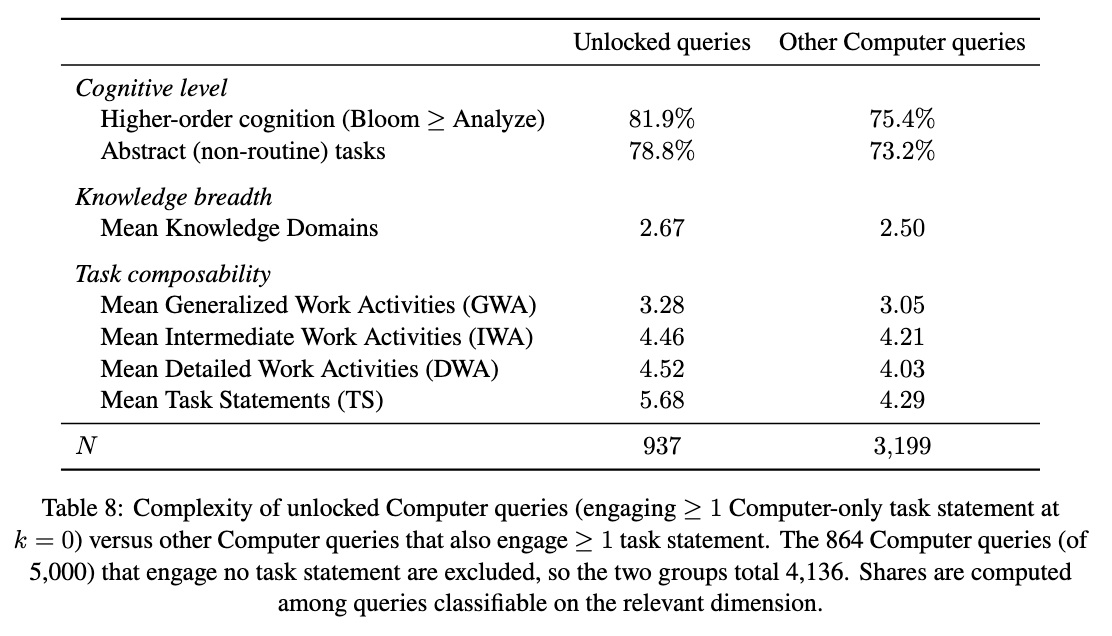
Finding 6: 23% of Computer queries include a work activity never attempted in Search, and this increases to 41% if we relax the tolerance threshold.
These newly unlocked tasks are typically more demanding, in the sense that they require more complex reasoning and involve more knowledge domains and work activities, which makes them likely too costly to tackle with Search alone.
Discussion
In this paper, we study the downstream, task-level economic implications of the shift from conversational assistants to agents: by completing tasks more autonomously and at higher quality, agents substantially reduce required human time and cost and reallocate activity toward broader, more demanding work.
The autonomy results clarify why these downstream effects arise. Agents remove the manual task-decomposition and execution loop in conversational sessions, so users no longer need to translate goals into step-by-step actions themselves. Before agents, the binding constraint was less about information access and more about execution capacity. Once execution is delegated to the agent, users reallocate time toward higher-order work—setting direction, verifying outputs, and extending tasks.
Freeing up human execution capacity with machine work then drives the efficiency results: once agents take over the most time-consuming execution steps, the same tasks can be completed with far less human time and at much lower cost.
Existing evidence has largely focused on productivity, but our results suggest that a pure productivity framing understates the impact of agents. Although the time and cost savings are large, the more consequential change may be scope expansion: users step across occupational boundaries and expertise levels to take on work they previously would not attempt.
We note a few important caveats.
The 90-day observation window (February 27–May 27, 2026) captures an early-adoption period in which users tend to be AI-native, so our results primarily reflect behavior in this group. These users are also actively experimenting and adapting in a fast‑evolving product space, so the patterns we document here may not fully generalize to later, more mainstream cohorts.
The matched‑query design, though useful for holding task content fixed, only covers Computer queries that have close Search counterparts, so our autonomy and efficiency estimates are local to that subset. Many Computer queries have no such analogue, but their higher average complexity suggests that the underlying gains on those queries are likely to be even larger.
Although sessions offer a natural unit for organizing tasks, they are an imperfect proxy: in practice, a user might stretch a single task across multiple sessions, and conversely, pack several unrelated tasks into a single session.
The efficiency estimates rely on assumed per‑tool human‑equivalent times, human supervision time, and LLM-based time estimates, so some measurement error is inevitable. While the breakeven and sensitivity analyses indicate that our qualitative conclusions are robust to substantial mis‑measurement, the absolute magnitudes should be read as approximate orders of magnitude.
The scope analysis relies heavily on LLM-based classification, which also introduces measurement error. However, the magnitude of the gaps suggests that the patterns are unlikely to be driven by classification noise alone.
We measure user behavior only within the Perplexity ecosystem, so we may miss parts of users’ broader workflows and tool use.
Our study focuses on the individual worker and task levels, so we leave open how firms, consumers, or the broader labor market respond to these shifts. A natural next step is to study how these micro-level changes aggregate into organizational and labor-market outcomes.
If agents lower barriers to crossing occupational boundaries and expertise levels and reduce coordination costs, individuals may be able to produce outputs that previously required teams. Future work could link agent usage to downstream workplace outcomes to assess whether agents are directed primarily toward accelerating existing workers, enabling workers to assume cross-occupational responsibilities, or creating new categories of economically viable work. Our early evidence points to all three, but firm-level production and employment data are needed to assess how agents reshape the bundling of work, the definition of roles, and the structure of teams.
Link to paper.
Prior research has already documented the adoption and productivity gains from conversational assistants relative to pre-LLM workflows (see the Related Work section in the paper). So we adopt this as a stronger baseline when evaluating agents; using weaker baselines would further amplify the estimated effect sizes.
Growth is based on the universe of Computer and Search queries in the study period. Use case is based on a random sample of 100,000 Computer queries.
Matched sessions are based on a sample of 10,000 matched-pairs where the initial Search and Computer queries are near-identical (cosine similarity > 0.99).
Follow-up query analysis is based on a random 1,000-session subset of the 10,000 matched sessions with at least two turns/queries.
User dissatisfaction is based on the sentiment of the next-turn query.
Cross-occupation analysis is based on a random sample of 8,000 users and all their Search and Computer queries (1,000 in each occupation cluster). Primary occupation is inferred from the mode query topic.
Cognitive complexity, knowledge domain, work activities, and new tasks unlocked are all based on a random sample of 5,000 Search queries and 5,000 Computer queries from the same 5,000 users.
Your findings resonate with my experience using agents. In many ways, agents make the most sense for tasks on which our expertise and authorship are least important, and for which ease/speed of automation exceeds concerns about expertise, precision, or ownership of the work. Your work helps clarify the tasks on which people will be willing to seek task augmentation versus full automation.
Agents do not just make existing work faster. They expand the work a person can attempt.
That scope expansion is exactly where the authority problem shows up.
If agents let users cross occupational boundaries, chain tools, prepare artifacts, and move toward execution, then the missing layer is not another productivity metric. It is the boundary between:
“the AI prepared this”
and
“this consequence is authorized.”
That is what I’ve been building toward with MFOS.
The more agents expand scope, the more we need approval continuity, execution continuity, and a clear human commit boundary before consequential actions happen.
AI can do the work.
The human still needs the final say.